CockroachDB Meets Collate: Distributed SQL with Built-in Metadata Management
Understanding CockroachDB's Place in the Ecosystem
CockroachDB occupies an interesting position in the database landscape. The name itself tells the story: you can't kill a cockroach. This philosophy drives the entire architecture. As a distributed system, if one node fails, others continue operating. There's no single point of failure, no maintenance windows that require downtime.
What makes CockroachDB particularly valuable is its ability to bridge two worlds. It's built for use cases that might otherwise push teams toward NoSQL solutions, while maintaining the consistency and familiarity of SQL. You get the scalability and resilience of distributed systems without sacrificing the transactional guarantees and query capabilities that SQL provides.
This isn't a database for analytics workloads, such as Snowflake. Instead, it excels at real-time operational systems. Think of use cases where data needs to be highly available and consistent: the manifest metadata in Apache Iceberg, control plane data for distributed systems, or any application where downtime simply isn't acceptable. A companion video to this blog can be found here.
Setting Up the Integration
Whether you're running a local instance, using CockroachDB Cloud, or deploying on AWS, the connection process remains straightforward: select CockroachDB, provide your connection details, and you're ready to begin cataloging.
CockroachDB includes built-in tooling for predefined workloads, making it easy to generate test databases. Popular options include the KV (key-value) workload, the "mover" database (simulating a ride-share application), and TPC-C benchmark datasets. These workloads provide realistic schema structures for testing and demonstration purposes.
Once connected, Collate's ingestion agents work exactly as they do with any other database connector. You can configure schema filters and database filters to control what gets cataloged. The agents run, catalog completes, and you're looking at your CockroachDB metadata in the Collate interface.
Collate's documentation site provides detailed prerequisites, including the exact SQL commands you need to run to grant proper permissions to your service account. This level of specificity helps avoid common permission-related issues during setup.
Starting from Collate's landing page, navigate to Settings > Services > Databases, where Cockroach can be easily located among the extensive list of supported connectors. The process looks like this:
1. Navigate to Settings: Begin by accessing the services section in Collate's settings.


2. Add New Database Service: Select “Services”, then “Databases”, then "Add New Service" and search for Cockroach in the service list.






3. Configure the Connection:
You'll need to provide:
- Username
- Auth Configuration Type
- Password
- Host and port information


What You Get Out of the Box
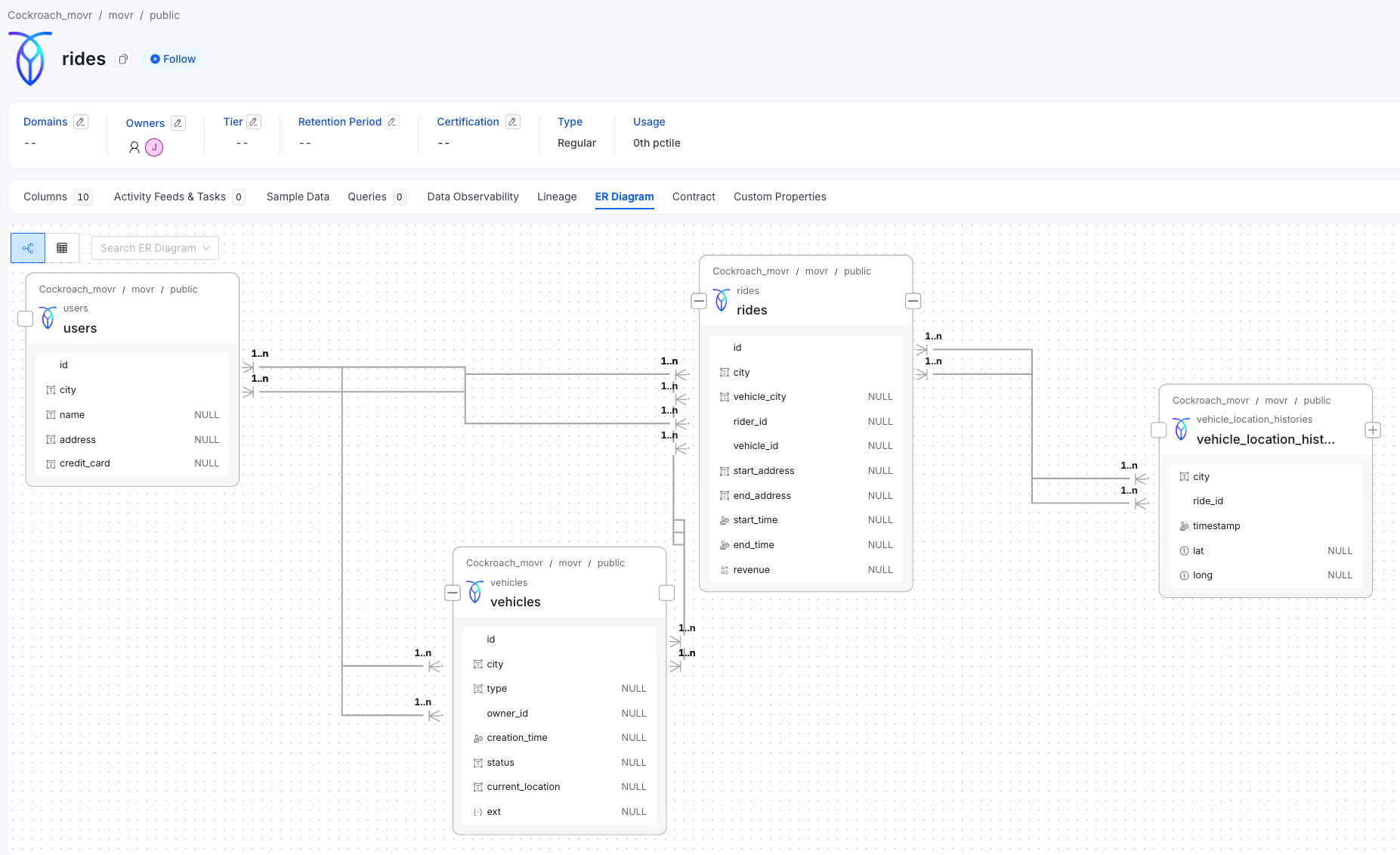
The initial catalog of a CockroachDB database has immediately useful information from its available sample tables. Taking the "mover" database as an example, Collate automatically discovers the public schema, identifies tables and views, and maps the relationships between them.
Opening a specific table, such as the rides table, displays sample data, foreign key relationships, and column details. The entity relationship diagram (ERD) provides that quick visual confirmation that your structure imported correctly and shows how tables connect. For anyone who's spent time manually documenting database schemas, these automatically generated ERDs offer immediate value.

Views receive the same treatment. A customer summary view shows not just its structure but also its lineage, tracing back to the source tables that feed it. You can examine the actual SQL that defines the view, all without leaving the Collate interface.
Lineage: The Differentiator
Data lineage is one of Collate's strongest capabilities and integrates seamlessly with CockroachDB. Understanding how data flows through your systems typically requires either extensive documentation or finding someone who remembers how everything was built. Collate extracts this information automatically.

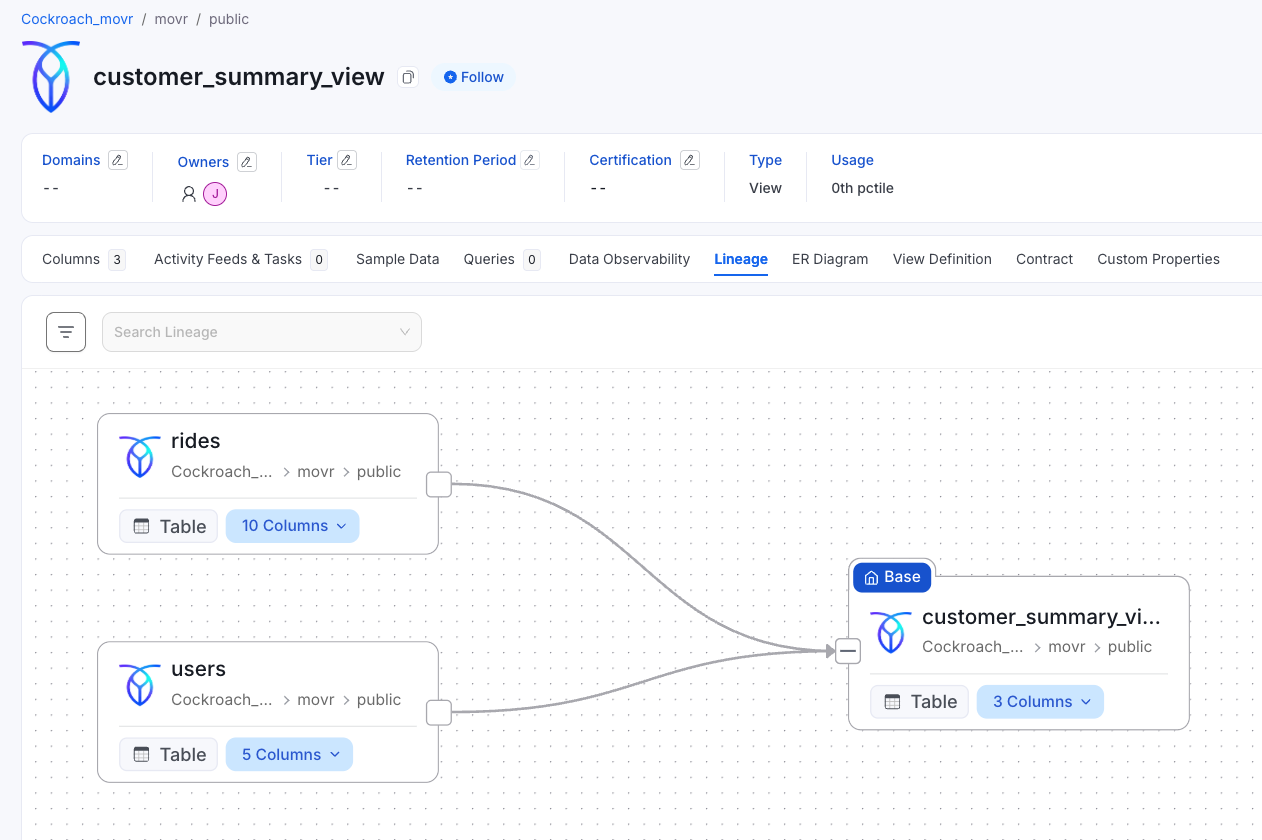
In the customer summary view of the mover database, lineage shows that it joins two distinct tables. This isn't just a static diagram; it's an interactive exploration tool. Click on any element to dive deeper, trace dependencies forward or backward, and build a complete picture of your data flows.
This automatic lineage extraction becomes particularly powerful as systems grow more complex. When you're onboarding to a new team or troubleshooting an issue, being able to visualize these relationships without hunting through documentation saves considerable time.
AskCollate: Natural Language Discovery
A new and exciting feature is AskCollate, the natural language interface for querying metadata. Instead of learning navigation patterns or memorizing where specific information lives, you can simply ask questions in plain English.
"Give me detailed information about the rides table in CockroachDB" returns a summary, column information, primary keys, and clickable links to related resources. The system maintains context, so follow-up questions build on previous ones. "Show me the lineage" works exactly as you'd expect, displaying the lineage diagram without requiring any knowledge of where that feature lives in the interface.
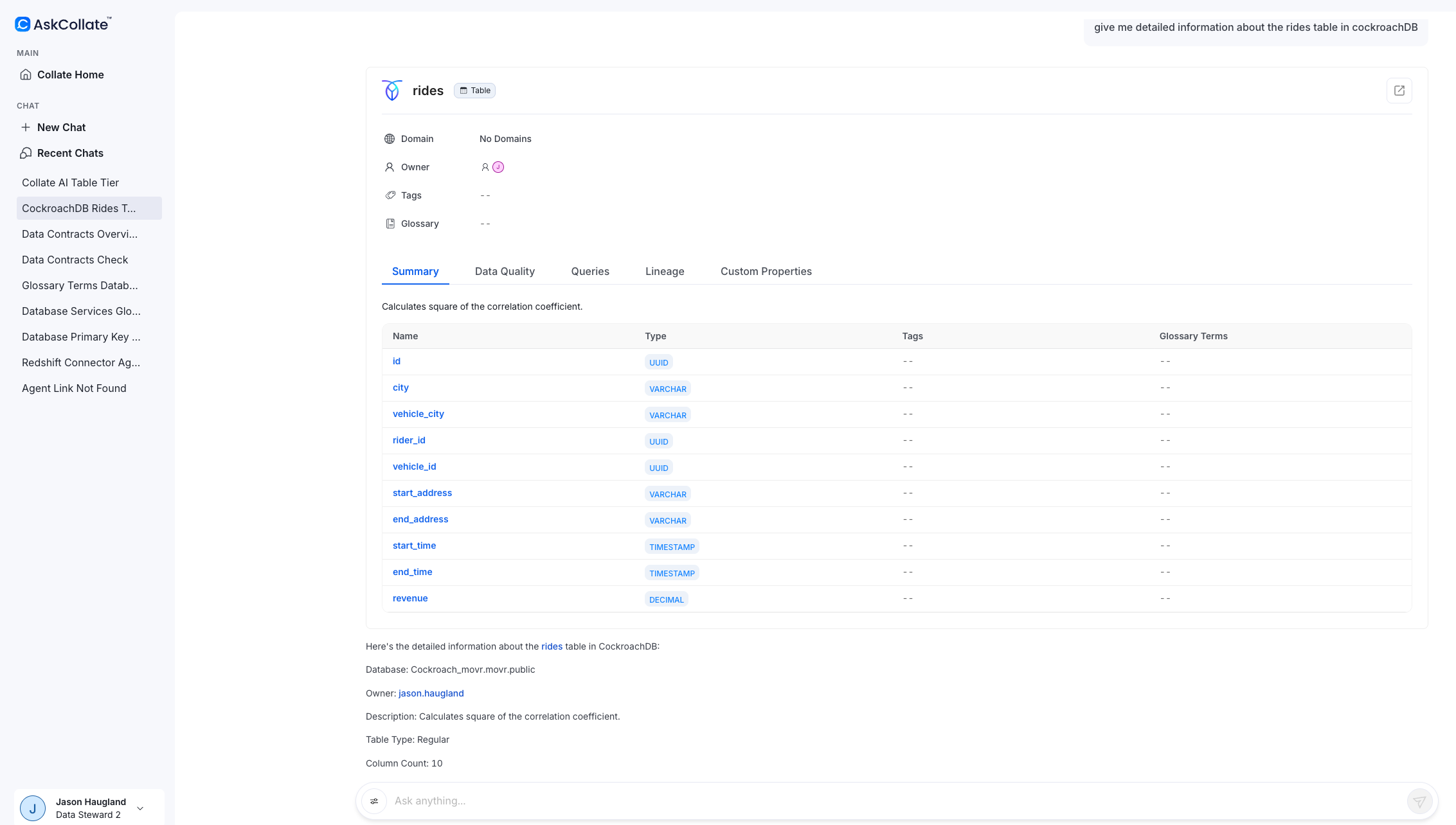
This conversational approach can fundamentally change onboarding. New team members can start extracting value immediately rather than spending days learning the tooling. Ask about view definitions, query which CockroachDB databases are available, or explore relationships between tables, all through natural language.
Conclusion
The combination of CockroachDB's resilient distributed architecture with Collate's metadata management creates a foundation for building reliable, well-documented data platforms. You get a database that won't go down paired with tooling that ensures you understand what's in it.
For teams running CockroachDB, adding Collate provides immediate visibility into schemas, relationships, and lineage. For teams already using Collate, CockroachDB becomes a viable option for operational workloads that demand high availability and SQL consistency.
The integration requires no special effort; cataloging happens automatically, and the resulting metadata is immediately queryable through both traditional navigation and natural language interfaces. Sometimes, the best integrations are the ones that just work.
To explore further, consider the Collate Free Tier for managed OpenMetadata or the Product Sandbox with demo data.
Fashion Retailer Mango’s Data Journey with Collate
Read the case study

Sign up to receive updates for Collate services, events, and products.
Share this article



Ready for trusted intelligence?
See how Collate helps teams work smarter with trusted data