Connecting Collate® to Snowflake: Beyond Basic Data Cataloging
Introduction
When most people think about data catalogs, they picture static inventories of tables and columns. But what if your catalog could do more than just list your data assets? What if it could actively manage metadata, track usage patterns, and even help control costs across your data ecosystem?
Collate is an AI-enabled platform designed to help data teams organize, govern, and optimize their data assets. It focuses on automating tasks like data discovery, quality assurance, observability, and compliance to boost productivity and reduce costs. By using Collate, you can quickly find and collaborate on key data assets across various sources, with over 90 connectors. Generate secure and permission-aware insights from a unified knowledge graph, ensure regulatory compliance, such as GDPR, and build a self-service data culture that accelerates development and problem resolution.
Snowflake has become one of the most popular platforms for data lakes and warehouses, but managing metadata, lineage, and data quality across large datasets can quickly become overwhelming. That's where Collate steps in, offering a comprehensive data catalog solution that seamlessly integrates with Snowflake, bringing all your data management needs under one roof. A companion video to this blog is available on YouTube.
Setting Up the Connection
The initial setup process for connecting Collate to Snowflake is straightforward. Starting from Collate's homepage, the process begins in Settings > Services > Databases, where Snowflake can be easily located among the extensive list of supported connectors. The process looks like this:
1. Navigate to Settings: Begin by accessing the services section in Collate's settings.


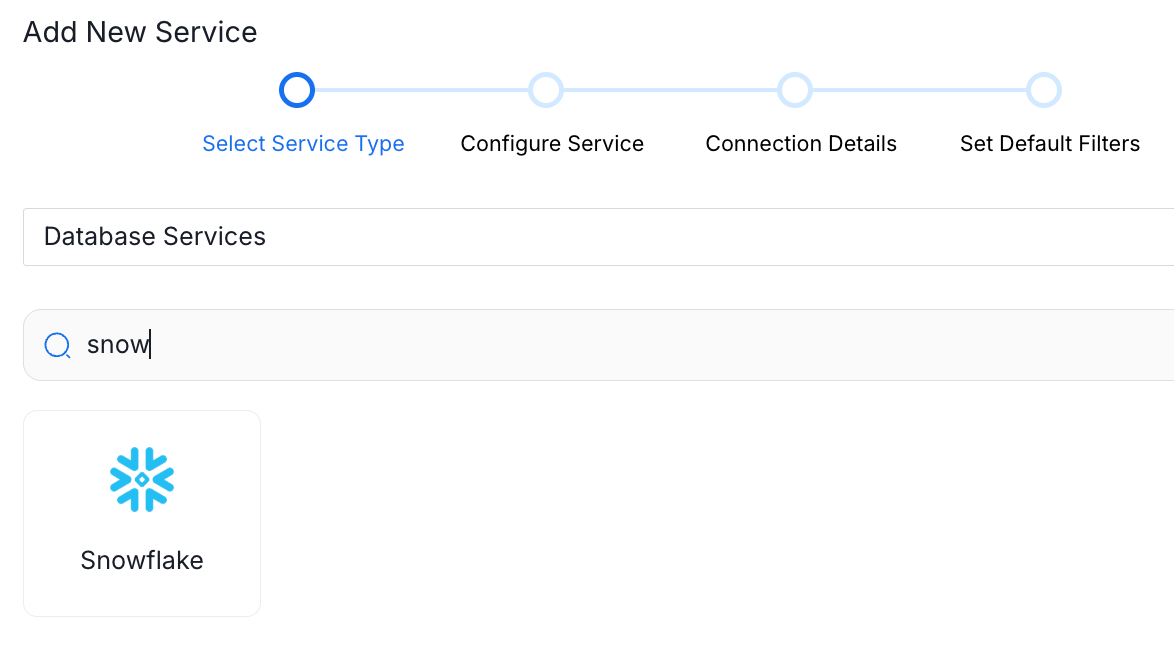
2. Add New Database Service: Select “Services”, then “Databases”, then "Add New Service" and search for Snowflake in the service list.






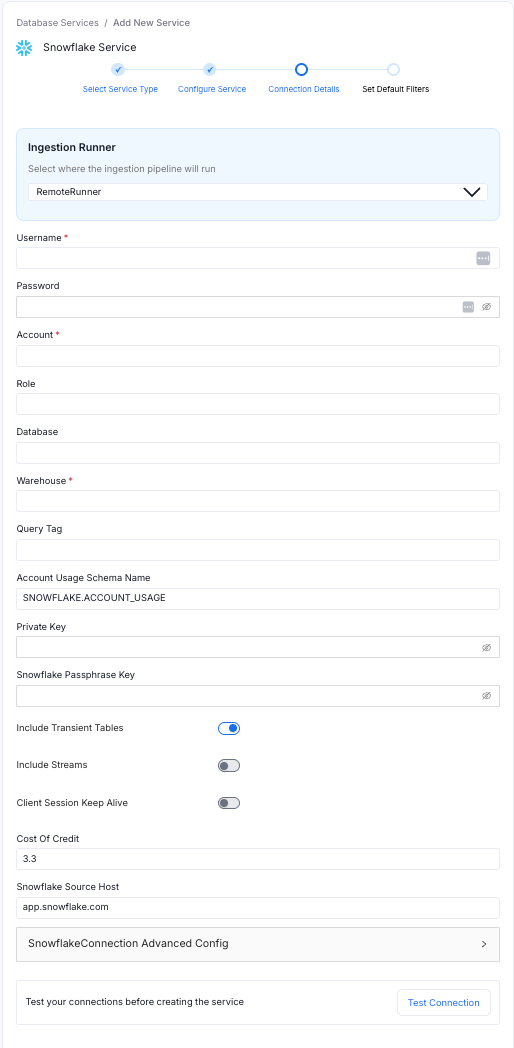
3. Configure Connection Details:
- Enter a descriptive name for your database service
- Provide database credentials (username, password)
- Account identifier
- Warehouse name
- Private key and passphrase (if used)

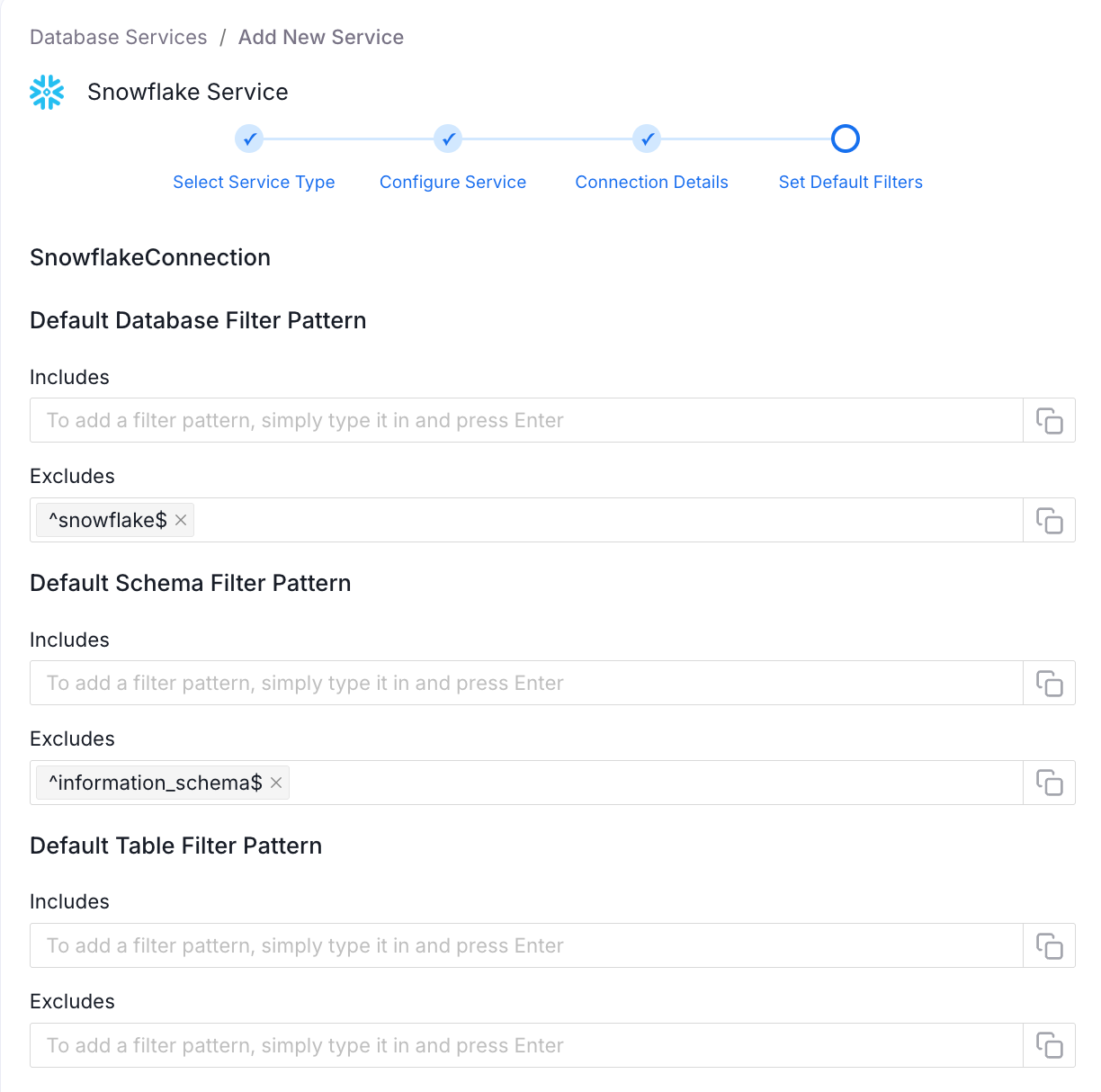
Collate uses filters to control what data is ingested, databases, schemas, or tables, via names or regular expressions (regex). Out of the box, it excludes system schemas, such as "information_schema" or "performance_schema", to focus on user data.
Accept the defaults for a full ingest, or customize: for instance, include only schemas matching "^prod_.*" to target production data. Use the filtering options to control which databases, schemas, or tables are imported, thereby reducing unnecessary bloat.

Reverse Metadata
One of the more impressive features of Collate is the reverse metadata capability. Here's how it works: With the Reverse Metadata feature set up and configured, when you add/change/remove owners, tags, or descriptions in Collate, the changes are automatically pushed back to Snowflake in near real-time.
This bidirectional synchronization addresses a critical issue: while Snowflake excels as a data warehouse, it's not designed to serve as a metadata management command center. Collate fills this gap, providing the governance and curation tools that business analysts and data stewards need, while ensuring that metadata enhancements are immediately available to data consumers in Snowflake.
Usage Analytics
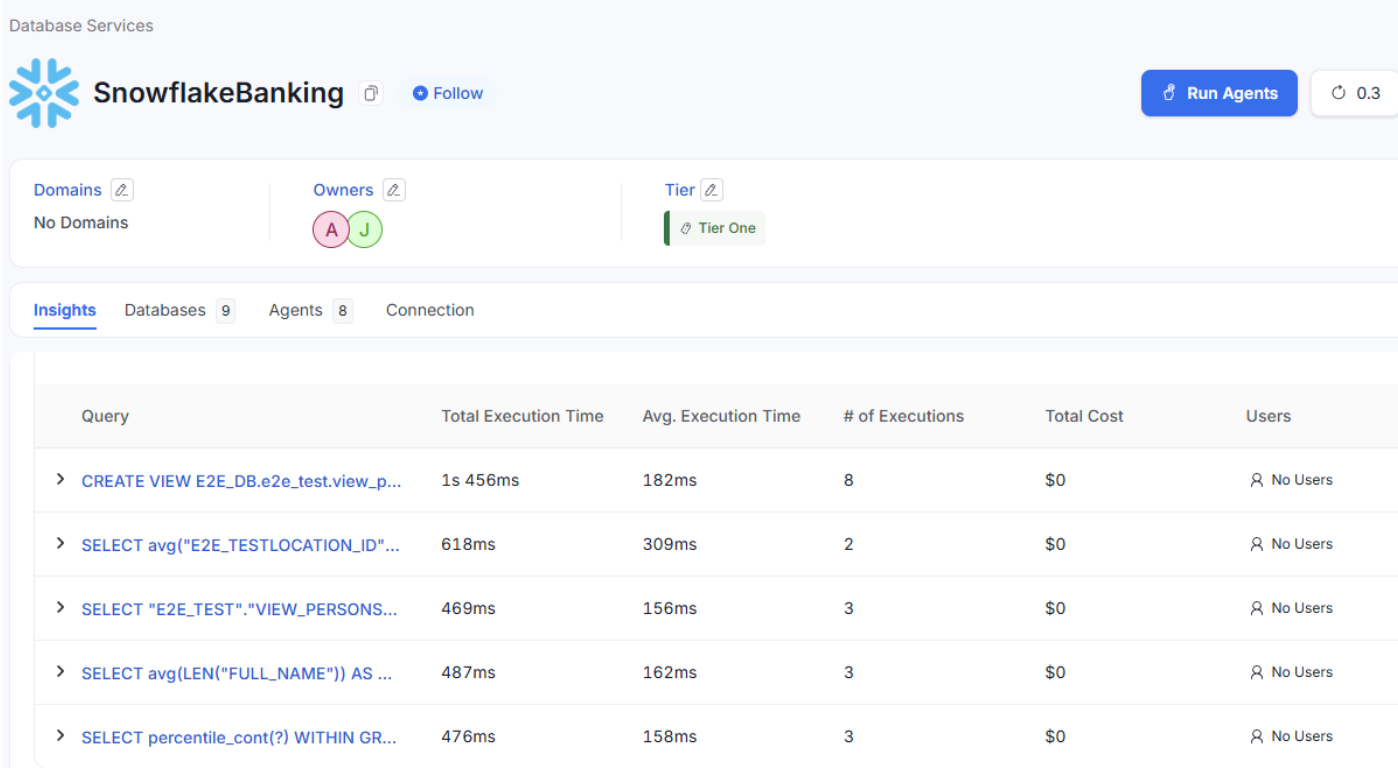
Beyond metadata management, Collate also provides visibility into how your Snowflake environment is being used. The platform tracks and displays:
- Most frequently accessed data assets
- Query execution times (both total and average)
- Number of query executions
- Total cost per query
That last point is significant. By configuring cost per credit in the connection settings, Collate can translate Snowflake's credit consumption into actual dollar amounts. This gives data teams easy visibility into which queries and datasets are driving costs.
This is even more helpful for organizations running multiple data warehouses (Snowflake, Databricks, Redshift, BigQuery). Collate provides a unified view of usage and costs across all platforms. Instead of logging into multiple systems to understand your data consumption patterns, you get everything in one place.

Why The Analytics Matter
The combination of metadata management, usage tracking, and cost visibility addresses three critical challenges facing data teams today:
Governance at Scale: As data environments expand, manual metadata management becomes increasingly impractical. Collate's AI-powered tagging and automated description generation, combined with reverse metadata sync, means governance policies can be enforced consistently across your entire data estate.
Cost Control: Snowflake's consumption-based pricing model can lead to unexpected costs, particularly for teams that are still learning the platform. Having query-level cost visibility helps identify expensive operations before they significantly impact your budget.
Cross-Platform Visibility: Modern data teams typically work with multiple warehouses. Collate's ability to provide unified analytics across different platforms eliminates the need to context-switch between multiple vendor interfaces.
The Symbiotic Relationship
It’s worth noting how this integration creates a true partnership between the platforms. Snowflake provides the computational power and storage, while Collate handles the metadata curation and governance workflows. Neither platform tries to be everything; instead, they complement each other's strengths.
This symbiotic approach enables you to leverage Snowflake's policy-based security features while utilizing Collate's more sophisticated tagging and classification tools. Tags applied in Collate can trigger data masking policies in Snowflake, creating an end-to-end governance workflow that spans both platforms.
Conclusion
As data environments become more complex and distributed, tools that can provide unified visibility and control become increasingly valuable. The Collate-Snowflake integration demonstrates how modern data catalogs should work, not as passive inventories, but as active management platforms that enhance and extend the capabilities of your existing data infrastructure.
To explore further, consider the Collate Free Tier for managed OpenMetadata or the Product Sandbox with demo data.
Fashion Retailer Mango’s Data Journey with Collate
Read the case study
Sign up to receive updates for Collate services, events, and products.
Share this article



Ready for trusted intelligence?
See how Collate helps teams work smarter with trusted data