Connecting dbt to Collate®: Enriching Your Data Lineage
Introduction
When data teams invest time curating metadata in dbt, adding descriptions, documenting transformations, and defining test cases, that work shouldn't stay siloed in your transformation layer. Collate's dbt connector bridges this gap, pulling that valuable context directly into your data catalog where it can enrich the entire data landscape. This article will cover the integration and some features of dbt and Collate. A companion video to this blog is available on YouTube.
Why Connect dbt to Your Catalog?
dbt has become the backbone of modern data transformation workflows. Whether you're using it as a complete ETL tool or as an additional metadata layer on top of your data warehouse, dbt captures critical information about how your data assets relate to each other. The challenge? That information lives in manifest files and dbt Cloud projects, separate from where your team discovers and understands data assets.
Collate solves this by automatically ingesting dbt metadata and weaving it into your broader data lineage story.
Setting Up the Connection
The initial setup process for connecting Collate to BigQuery is straightforward. Starting from Collate's landing page, navigate to Settings > Services > Pipelines, where dbt can be easily located among the extensive list of supported connectors. The process looks like this:
1. Navigate to Settings: Begin by accessing the services section in Collate's settings.


2. Add New Pipeline Service: Select “Services”, then “Pipelines”, then "Add New Service" and search for dbt in the service list.






Supports Both dbt Cloud and dbt Core
Collate accommodates both dbt Cloud and dbt Core, though the setup differs slightly between them.
For dbt Cloud, you're working with a traditional connector. The configuration requires your host URL, discovery API URL, account ID, and authentication tokens. Once configured, Collate uses these credentials to access the appropriate manifest files from your dbt Cloud environment.
In dbt Core, the process involves setting up an ingestion workflow that explicitly specifies the location of your manifest files. This includes both your standard metadata manifest and, optionally, your test case manifest file.
Both approaches are thoroughly documented, making implementation straightforward regardless of which dbt variant your team uses.

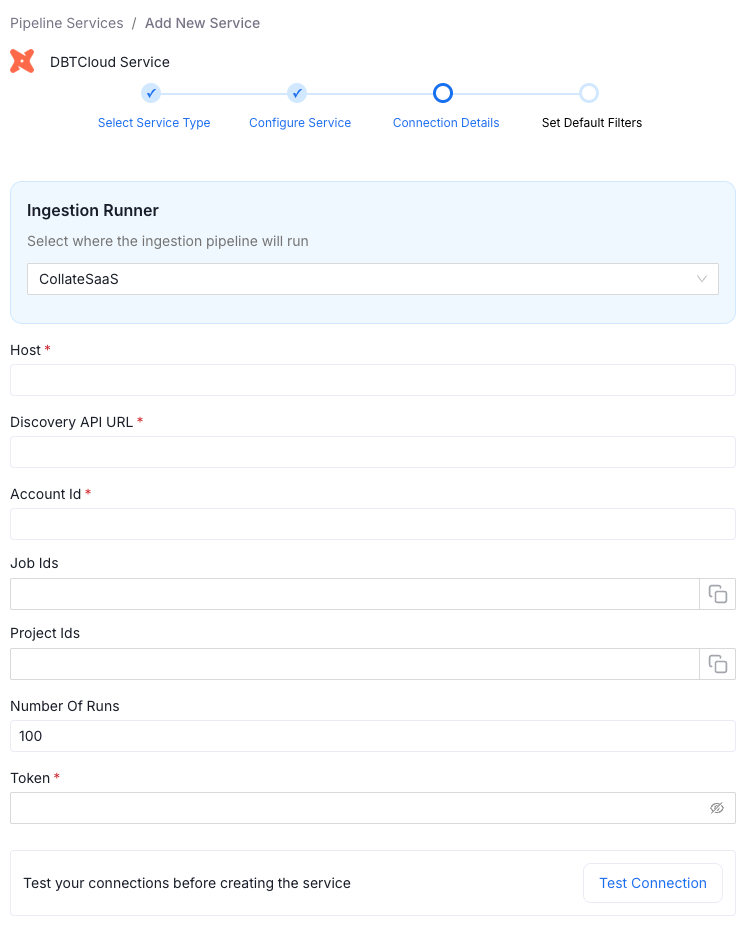
Consistent Configuration
Setting up the dbt connector follows familiar patterns if you've configured other Collate connectors. You'll find standard filtering capabilities to focus on specific projects or models. If you're connecting lineage across multiple database services, you can specify those relationships during configuration.
The consistency in how Collate handles connectors reduces cognitive load when adding new integrations to your catalog. The principles you've learned for setting up warehouse or BI tool connectors apply equally to dbt.
Visual Lineage With Pipeline Context
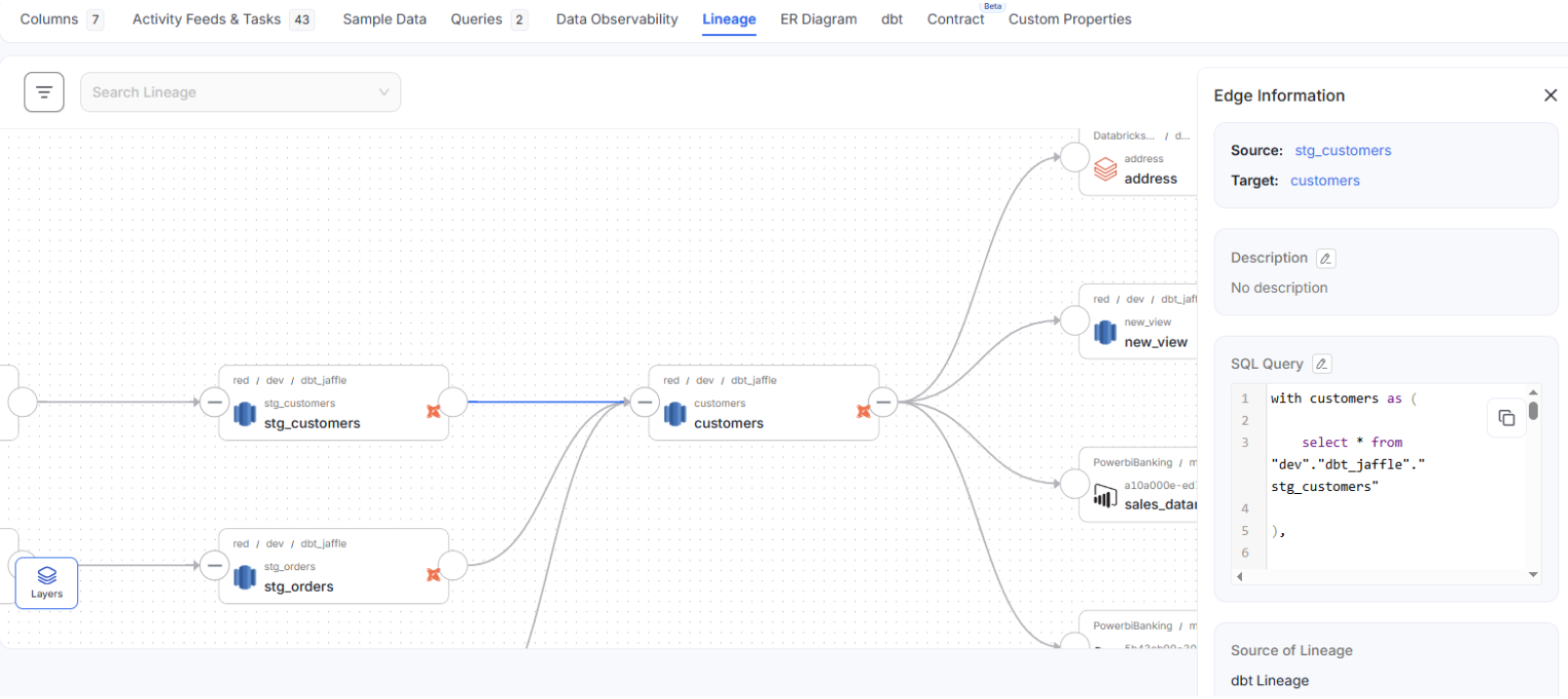
The most immediate benefit shows up in lineage diagrams. Instead of seeing a direct connection between two tables, you'll see a distinct node representing the dbt transformation between them. This pipeline node makes it immediately clear that a transformation tool sits in the middle of your data flow.

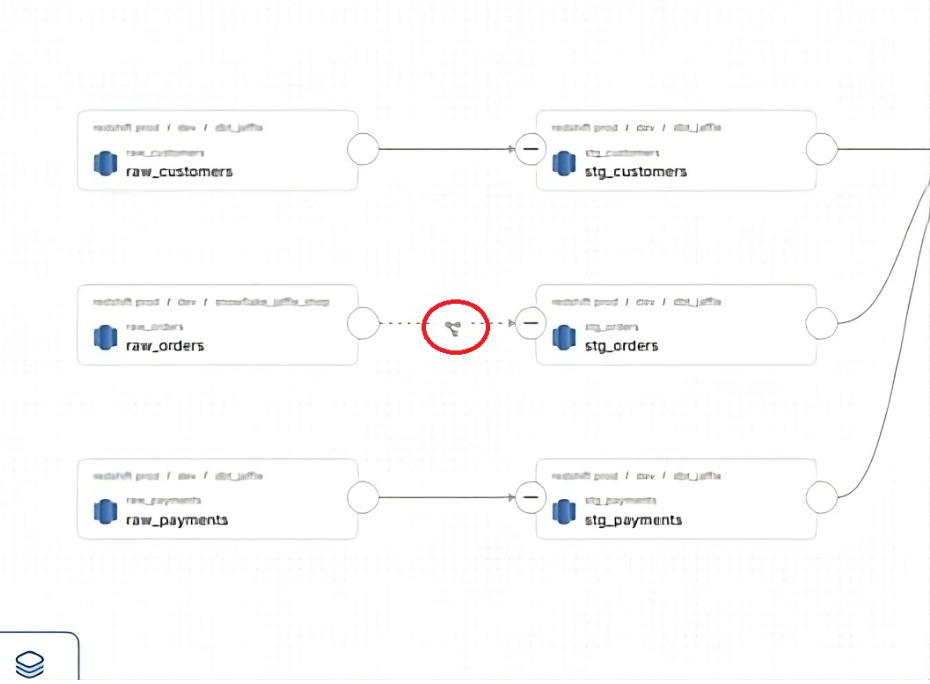
Click that node to view the SQL query that powers the transformation, assuming one exists in the dbt model. This level of transparency helps data consumers understand not only that Table B derives from Table A, but also precisely how that derivation occurs.
The visual markers extend beyond lineage diagrams. Tables touched by dbt display a recognizable dbt logo tag, making it instantly obvious which assets have been curated through your transformation pipeline. Even entity-relationship diagrams at the schema level show these dbt indicators, providing consistent visual cues throughout the platform.

Automatic Enrichment Through Manifest Files
The real power lies in what happens after you configure the connection. When you run the data agent, the only agent required for dbt connections, Collate pulls the manifest file contents and automatically associates them with existing data assets in your catalog.
This means that descriptions, tags, ownership information, and transformation logic documented in the dbt flow are directly imported into Collate. You're not manually mapping or duplicating this work. Enrichment occurs automatically during ingestion.
Bringing Test Cases Into Your Catalog
One handy capability: importing dbt test cases directly into Collate. By pointing to your test case manifest file during configuration, you can run those existing test cases within Collate itself.
This eliminates duplicate work. Rather than recreating data quality checks in multiple tools, you leverage the tests you've already defined in dbt. Your team gains a single platform for understanding data quality without losing the rigor you've built into your transformation pipeline.
End-to-End Lineage Across Your Stack
The dbt connector doesn't exist in isolation. It integrates with Collate's broader connectivity to create a complete lineage across your entire data stack. For teams running standard configurations, Snowflake, Databricks, or Redshift, for example, as the warehouse; dbt for transformation; and Tableau or Power BI for visualization, Collate provides automatic cross-source lineage out of the box.
You can trace a metric in a dashboard back through the dbt models that shaped it, all the way to the raw source tables where the data originated. This end-to-end visibility becomes invaluable when debugging data issues, understanding impact analysis for schema changes, or simply onboarding new team members who need to understand your data flows.
Conclusion
The value of dbt often lies in the discipline it brings to data transformation—the documentation, the version control, the testing. Connecting dbt to Collate makes that discipline visible across your organization. The work data engineers invest in curating dbt models becomes accessible to analysts, business users, and anyone else exploring your data catalog.
Rather than metadata living only where transformations happen, it surfaces where data discovery happens. That alignment is what turns a data catalog from a static inventory into an active tool for understanding your data landscape.
To explore further, consider the Collate Free Tier for managed OpenMetadata or the Product Sandbox with demo data.
Fashion Retailer Mango’s Data Journey with Collate
Read the case study

Sign up to receive updates for Collate services, events, and products.
Share this article



Ready for trusted intelligence?
See how Collate helps teams work smarter with trusted data