Collate vs. DataHub
Collate's Semantic Context Platform transforms metadata into shared meaning and automates data governance with AI agents. DataHub connects and catalogs metadata, but understanding your data requires more than indexing it.
Trusted by 3,000+ enterprise deployments worldwide







Why data teams choose Collate over DataHub

Shared understanding, faster insights
Shared meaning across people and AI to find, interpret, and use data the same way. Collate's semantic context graph powers Collate AI for conversational AI, analytics, and 7 specialized agents that automate metadata ingestion, lineage, documentation, classification, tiering, quality testing, and SQL optimization. DataHub provides an MCP server for connecting external AI tools, but teams must build or integrate agent capabilities themselves. Collate AI works out of the box.

One platform, total trust
Integrated discovery, lineage, quality, observability, and governance in a single architecture from day one. Collate's API-first ingestion runs on 4 core components instead of DataHub's 11 Kafka-dependent services, and has been benchmarked at 18x faster metadata ingestion from Redshift (10 minutes vs. 3 hours). Simpler architecture means faster deployment, lower infrastructure costs, and easier scaling.

Activate AI with confidence
Automated governance, classification, and data contracts ensure compliance at scale. Collate uses JSON Schema and RDF/DCAT to make your metadata LLM-ready and portable from day one. DataHub uses PDL (Pegasus Definition Language), a format developed for LinkedIn's internal use with limited external ecosystem adoption. JSON Schema is natively understood by every major LLM, while PDL requires a translation layer.
See your entire data estate in one place
Collate's Semantic Context Platform gives data teams a single view of every asset across 120+ sources. Discover, govern, and monitor data quality from one unified interface that works the same way across AWS, Azure, GCP, and on-premises environments.
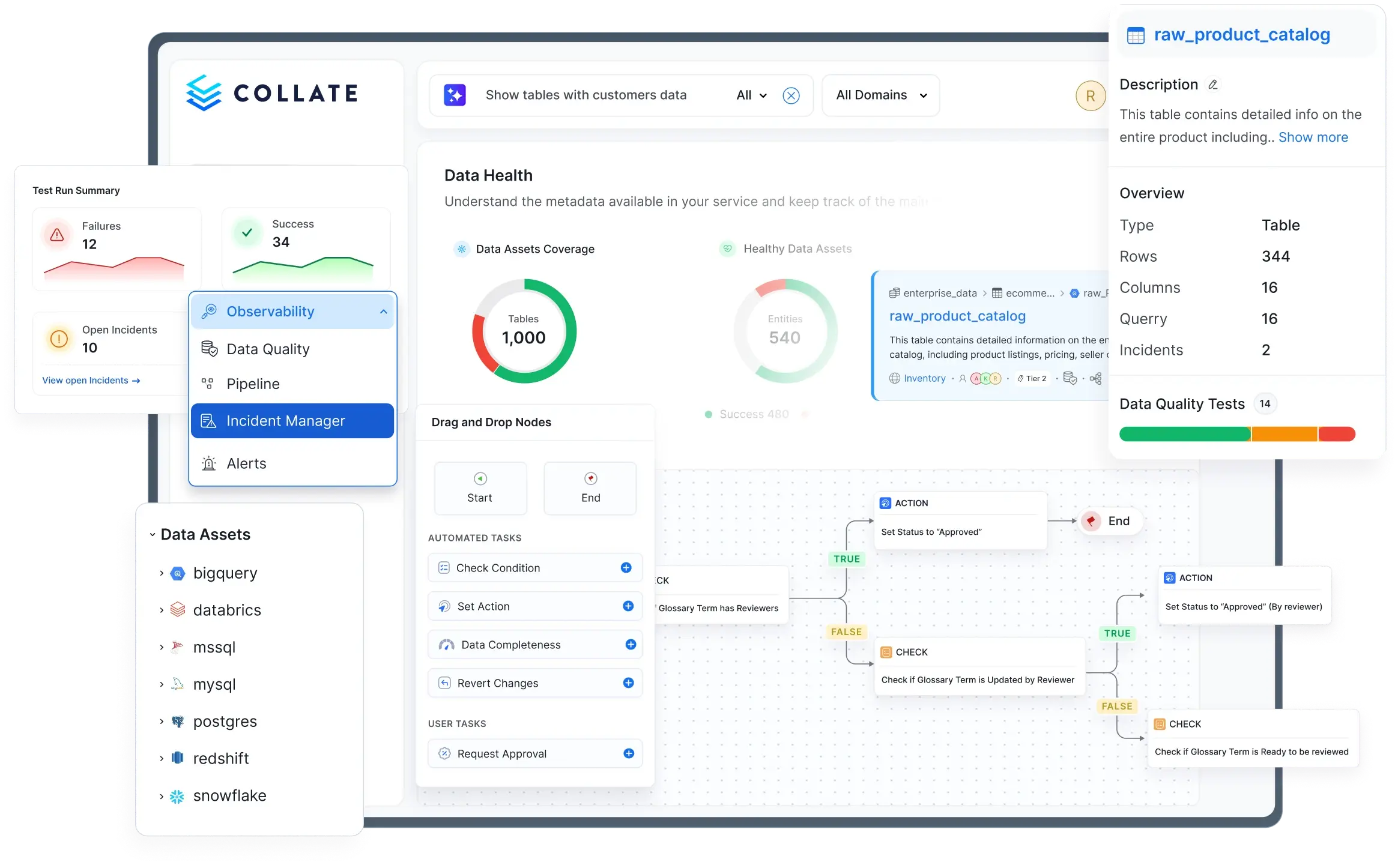
How Collate and DataHub compare
| Capability | Collate | DataHub |
|---|---|---|
| AI agent platform | ✓7 pre-built, specialized agents (Ingestion, Lineage, Documentation, Classification, Tiering, Quality, SQL) | ◐No pre-built agents, teams code agents on DataHub metadata with Agent Context Kit (code-based Python framework) |
| Conversational AI | ✓AskCollate native conversational AI for queries, quality, and data lineage, built directly on the Semantic Context Graph | ◐AskDataHub for natural-language queries over catalog, lineage, and data quality, catalog-backed, not graph-backed |
| AI analytics | ✓Natural language to charts, dashboards, and analytical insights — cross-verified against metadata for accuracy | ✗No native AI analytics capability |
| AI studio | ✓UI to build, customize, and deploy AI agents grounded in your semantic context and governance layer — no prompt engineering required | ◐Agent Context Kit (Python framework — code required) for building agents; no UI-based no-code builder |
| AI SDK | ✓Invoke Collate's built-in agents and embed semantic context into any external AI application programmatically | ✗No equivalent AI SDK |
| MCP server | ✓Enterprise MCP server with full permissions and governance layer enforced on every call | ◐MCP server bolt-on with no permissions layer; calls bypass governance controls |
| Semantic context layer | ✓RDF/DCAT for portable, AI-ready semantics; formal ontologies for mapping business concepts to data | ✗No RDF/DCAT or ontology support |
| Metadata standards | ✓JSON Schema (universal, LLM-native) | ◐PDL/Pegasus (LinkedIn-specific, limited external adoption) |
| Data quality & observability | ✓25+ built-in test types, DQ as Code, ML-based anomaly detection, freshness and completeness tracking, incident management — across 30+ databases, included from day one | ◐Configurable assertions for anomaly detection; fewer test types, only 4 database connectors, incident management on roadmap |
| Data contracts | ✓UI-driven creation with enforcement, run history, consumer-defined tests, ODCS support, and YAML import/export | ◐YAML code-based contract creation; assertions assembled separately; scheduled enforcement in SaaS only |
| Data lineage | ✓Column and table-level lineage across service, domain, and data product hierarchies; end-to-end impact analysis from source to dashboard | ✓Column-level lineage with impact analysis (core capability since LinkedIn) |
| Data product marketplace | ✓Build and publish data products using customizable forms built on Open Data Product Standard (ODPS); Domains for grouping and managing data assets with access control | ◐Data products via YAML with basic asset grouping and ownership assignment; no ODPS standard; no private/shareable designations |
| Connectors | ✓120+ native connectors, all included | ◐70+ connectors with Kafka-based ingestion pipeline; additional connectors are DIY via SDK |
| Incremental extraction | ✓Only syncs what changed since last successful run — benchmarked 18x faster from Redshift | ✗Full scan on every scheduled run |
| Architecture | ✓API-first, 4 core components, no Kafka dependency | ◐Kafka-based with 11 components; REST API push later added but full metadata sync recommended via Kafka |
What data leaders say about Collate
“OpenMetadata gives us a trusted foundation for AI-driven decision-making, letting our teams innovate faster and more confidently across the business.”
Website Builder Company

“Collate has transformed the way Mango manages its data assets and how its data users work together, unlocking new opportunities for collaboration, growth, and innovation.”
Global Fashion Retailer
“We kind of joke about OpenMetadata being a better version of DataHub, to some extent — mostly because DataHub is subjected to some of the technological choices that LinkedIn placed limits on.”
Co-creator of DataHub (Data Engineering Podcast, 2023)
About the Platforms
Collate is the Semantic Context Platform and the company behind the OpenMetadata project. It turns metadata into shared meaning so people and AI can work from the same understanding of data. Collate applies that semantic foundation across discovery, lineage, quality, observability, and governance to enable trusted analytics, explainable AI, and automated governance at enterprise scale. Global 2000 companies and innovative startups rely on Collate to accelerate insights and build AI-ready data foundations. Headquartered in Silicon Valley, Collate is backed by world-class investors including Venrock, Unusual Ventures, and Karman Ventures.
DataHub is an open-source metadata platform originally created at LinkedIn and later commercialized as Acryl Data (now DataHub Cloud). The platform provides metadata cataloging, lineage, and governance capabilities built on a Kafka-based event-driven architecture using LinkedIn's Pegasus Definition Language (PDL) for metadata schemas. Both DataHub's open-source project and commercial offering are Apache 2.0 licensed. DataHub has a strong lineage heritage from its LinkedIn origins and an active open-source community. The commercial DataHub Cloud offering adds managed infrastructure, enhanced AI features, and enterprise support.
FAQsCollate vs. DataHub
Collate offers AskCollate for conversational AI, AI Studio with 7 specialized agents (Ingestion, Lineage, Documentation, Classification, Tiering, Quality, SQL) that automate governance tasks out of the box, along with the ability to build custom agents via UI. An enterprise-grade MCP Server is available native within Collate with full permissioning controls and security. DataHub has no equivalent to Collate's pre-built agents or custom UI-built agents, and teams must build their own AI workflows on top of DataHub's Python framework. DataHub's MCP service is an add-on service without permissions controls. Additionally, Collate's AI services act on a Semantic Context Graph with portable RDF/DCAT semantics for understanding of the data landscape, while DataHub's run on a Kafka-based metadata service with more limited PDL schemas.
Collate has offered native, comprehensive data quality since day one with 25+ built-in test types, DQ as Code, anomaly detection, incident management, and DataDiff across 30+ database connectors, all included at no extra cost. DataHub offers configurable assertions with anomaly detection (Smart Assertions), but with fewer discrete test types, more limited connector coverage for quality scanning, and basic incident tracking with enhanced incident management still on the roadmap.
DataHub inherited its Kafka-based architecture from LinkedIn, where Kafka was originally created. Kafka was designed for large-scale event pipelines, not metadata ingestion. No major data warehouse (Snowflake, Databricks, BigQuery) emits real-time metadata events, so the Kafka layer adds operational cost and complexity without delivering true real-time benefits. Collate uses an API-first architecture with 4 core components instead of DataHub's 11, resulting in faster deployment, simpler operations, and benchmarked 18x faster metadata ingestion from Redshift. Collate's CTO, Harsha Chintalapani, is a Kafka PMC contributor who scaled Kafka to 5 trillion events per day at Uber and deliberately chose not to use Kafka for metadata ingestion.
Yes, both are Apache 2.0 licensed with full source code availability. The key difference is metadata standards, not licensing. Collate uses JSON Schema, a universal standard supported by every programming language and natively understood by LLMs. DataHub uses PDL (Pegasus Definition Language), developed for LinkedIn's internal use with limited adoption outside LinkedIn. As DataHub's own co-creator Mars Lan acknowledged, 'DataHub is using Pegasus, which is a very weird language developed by LinkedIn. Even though it's open source, it's not super popular outside LinkedIn.'
Collate uses incremental extraction by default, syncing only metadata that changed since the last successful pipeline run. This approach has been benchmarked at up to 18x faster than DataHub for Redshift ingestion (10 minutes vs. 3 hours). DataHub performs full metadata scans on every scheduled run through its Kafka-based pipeline. For large data estates, the difference in ingestion time, compute costs, and source system load is substantial.
Collate provides UI-driven data contract creation where producers and consumers jointly author contracts with schema validation, SLA tracking, freshness guarantees, and built-in quality tests tied directly to the contract. Contracts include run history with pass/fail status over time and support YAML import/export for Open Data Contract Standard compatibility. DataHub supports contract creation through its UI, but contracts require assembling pre-built assertions separately, and scheduled enforcement is available in the SaaS offering only.
Yes. Both Collate (via OpenMetadata) and DataHub offer self-hosted deployment under Apache 2.0 licensing. The key architectural difference is operational complexity. Collate runs on 4 core components (Jetty, MySQL, ElasticSearch, and the application) with no Kafka dependency. DataHub requires 11 components including Kafka, Zookeeper, and multiple microservices, resulting in higher infrastructure costs and operational overhead. Both also offer managed SaaS options, and Collate additionally provides BYOC and Hybrid Runner deployment models.
Collate uses JSON Schema for strongly typed, self-documenting metadata that is natively understood by LLMs. It supports RDF/DCAT for semantic richness and the Open Data Contract Standard for portable data contracts. DataHub uses PDL (Pegasus Definition Language), a LinkedIn-developed format with limited tooling outside the Java ecosystem. While DataHub data is exportable, the PDL format may require conversion for integration with external systems and LLMs.
Mars Lan, co-creator of DataHub, made notable comments on the Data Engineering Podcast in 2023. He said, 'We kind of joke about OpenMetadata being a better version of DataHub' and acknowledged that 'DataHub is subjected to some of the technological choices that LinkedIn placed limits on.' He also noted that OpenMetadata 'didn't choose to build a point solution. They chose to build a platform' and praised the choice of JSON Schema as 'very well understood, standardized, and has a strong connection to Open APIs.'
Ready to see the difference?
See why data teams choose Collate's semantic intelligence over traditional metadata catalogs, with native AI agents, 25+ data quality tests, and 120+ connectors included.
Deployments
Members
Contributors