Your Text-to-SQL Problem is Not the LLM



When AI gets the right answer to the wrong question
An analyst opens a chat with the AI and asks a question that every product team runs each quarter. "What percentage of users made a purchase in the first, second, third, and fourth months after their initial purchase?" A general-purpose LLM with database access reads the schema and writes valid SQL, then dutifully returns a confident answer organized by month buckets.
Unfortunately, unbeknownst to the analyst, the number is wrong, and the way it is wrong is the interesting part. The model interpreted "month" as elapsed days from each user's first purchase. A user who bought on January 31 and again on February 1 ends up in month 0, even though the business reports cohort retention by calendar month. The correct interpretation truncates each user's start date to the first of the month, then counts purchases against those calendar boundaries.
As a data engineer, how would you catch something like this? The query executes without error, and the dashboard updates as expected. The output appears correct because it conforms to the structure the analyst requested. Unfortunately, the number on the slide just means something different from what the analyst typed and what business leaders expect.
The accuracy of text-to-SQL fails here for reasons that have very little to do with the LLM. Most enterprise data estates do not encode meaning where the model can find it. When that meaning is missing, the model interpolates the hole with the most statistically-likely interpretation from its training data, and that interpretation is rarely how your business defines anything.
Why does the same LLM collapse on real enterprise data
The Spider benchmark has measured text-to-SQL systems for almost a decade. On Spider 1.0, an academic dataset of 200 databases with curated schemas, top systems crossed 85% execution accuracy years ago, and the current state of the art sits above 90%. Spider 2.0 swaps those academic schemas for real enterprise databases drawn from production warehouses, complete with the messy naming and sparse documentation those environments tend to carry. The model class is unchanged. On that test, GPT-4o lands at 10.1% execution accuracy.
Other research teams have run their own variants of this experiment with similar findings,. The shape of the result stays consistent. A high-performing model on a clean, well-described database collapses when you point it at the kind of data ecosystems that exist in most enterprises.
A high-performing model on a clean, well-described database collapses when you point it at the kind of data ecosystems that exist in most enterprises.
Three things sit between the model and the right answer.
-
Ambiguity. Business terms mean something specific in your org and something else in the model's training corpus. "Star product." "Loyal customer." "Active account." A general-purpose LLM picks the most statistically similar interpretation, which is rarely the one your finance team uses on Monday mornings.
-
Schema complexity. Real warehouses have hundreds or thousands of tables. Naming conventions encode tribal knowledge that only the team that built them can decode. Joins require domain understanding that the model wasn't trained on. The model has to guess which of the seven tables called transactions, tx_log, or fct_revenue, answers the question.
-
Hidden business logic. Filtering rules, time-window definitions, and metric calculations live in someone's head, in a deck from two quarters ago, or in a Notion page nobody has opened since the analyst who wrote it left. The model has no way to recover that knowledge from the schema. Without an encoded rule, the model substitutes its best guess.
The cohort-retention failure from the opening fell in the third category. The "month" definition existed, but it only lived in the analyst team's head and not in the data. When your warehouse has 800 tables and a decade of accumulated naming inconsistency, you are not the exception. You are the average.
If your warehouse has 800 tables and a decade of accumulated naming inconsistencies, you are not the exception. Like an LLM, you're the average.
What semantic context means
The same general-purpose LLM, running against the same database and answering the same question, can return a wrong answer or a defensible one. The context the model reads before generating SQL decides which answer will be presented.
Two of the inputs that matter most also get the least airtime in vendor pitches. The first is an AI documentation agent that auto-generates and maintains column- and table-level descriptions across the context layer (what some vendors will claim their data catalog is). Most schemas have no descriptions at all, or descriptions written years ago by someone who no longer works there. A documentation agent fills that hole around the clock, so the model picks up the latest explanations of what the data represents.
The second is an AI profiling agent. It surfaces statistics about table usage and content, telling the model which tables are queried often, which are stale, and what the data looks like. The most plausibly named table is rarely the most relied-on one, and a profiling agent surfaces that difference.
The other layers are what most teams already think of when they hear "semantic." Business glossaries resolve term ambiguity. Knowledge centers capture business logic that would otherwise live in someone's head, like the rule that "loyal customer" means three or more purchases in twelve months. Metrics definitions pin down calculations like net revenue and monthly active users to the formulas the business uses to report them.
Designed well, these layers don't sit beside a data catalog as a separate product. They are the same semantic foundation that powers discovery, lineage, and quality across the platform, surfaced to the text-to-SQL agent as a unified semantic context layer. Collate AI, which includes Collate AI Analytics and AskCollate counts with a natural-language text-to-SQL sub-agent that reads from this foundation, inheriting the documentation written for the data assets, the glossary curated by governance, and the metrics validated by finance.

When a vendor describes their semantic layer, ask how the model knows which tables to query, not only what the columns are named.
That is the buyer test for any AI-powered data tool. A glossary alone does not answer the table-selection question. Documentation agents and profiling agents do.
Better context also produces a side effect on compute. When the agent has the right tables and the right definitions in front of it, it doesn’t burn tokens exploring wrong joins, retry failed query plans, or hit iteration ceilings before returning anything. The accuracy story and the cost story converge.
What semantic context did to text-to-SQL accuracy across three datasets
We ran the same evaluation across three datasets of increasing complexity. Both setups used Sonnet 4.5 as the underlying LLM. The only variable was whether Collate's semantic layer (the Collate Semantic Context Graph) was in scope.
-
Dataset A is an internal Collate-built dataset of medium difficulty, well-modeled, and richly documented.
-
Dataset B is the ACME Insurance benchmark from Sequeda et al., a public real-world analytical benchmark used elsewhere in the field.
-
Dataset C is a subset of the Spider 2.0-Snow benchmark, the hardest of the three, drawn from the sparse, undocumented enterprise schemas Spider 2.0 was built to expose.
Dataset C produced the headline result. Adding Collate's semantic layer lifted execution accuracy from 10.8% to 76.5%, a 7.1x accuracy improvement with more than 65 percentage points on the dataset closest to a real enterprise warehouse. On Dataset B, AskCollate reached 100%, matching results dbt published from their own evaluation across leading models. On Dataset A, AskCollate scored 93.8% against a base of 78.5%. The semantic layer helped most where the data was sparse and undocumented, the conditions that match most enterprise warehouses.
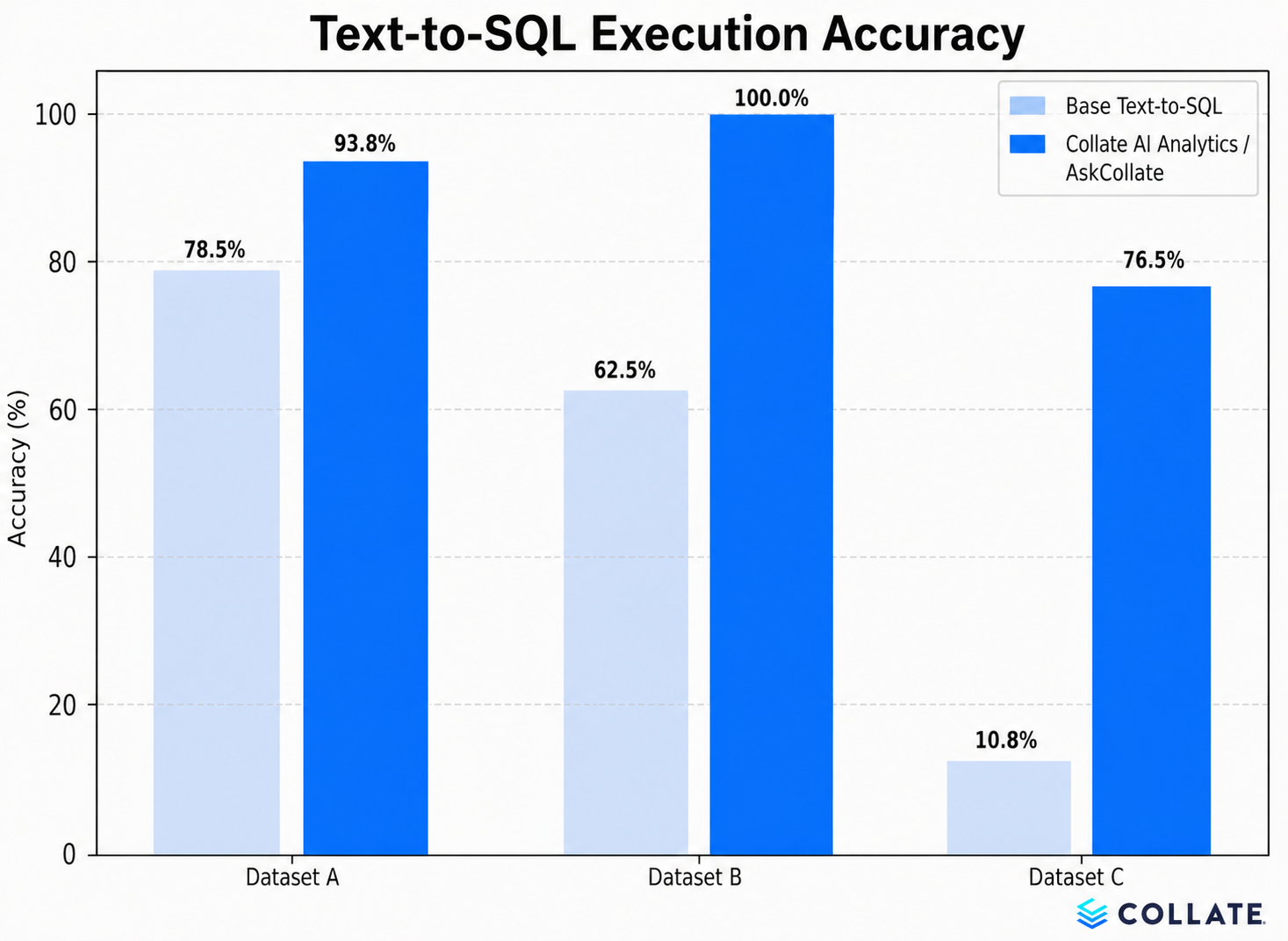
That lift came without requiring the data to be pre-modeled or registered in a separate semantic-modeling framework before the model could answer. The agent reads from the semantic platform's existing context, including documentation, profiling, and curated knowledge, and improves the model's grasp of the data as it stands. When that data is sparse, undocumented, or evolving, the same property carries the lift from demo into production.
Semantics is a category, not a feature
Text-to-SQL is one example of a broader pattern. Every AI workload that touches enterprise data suffers from the same context shortfall, whether it's a discovery agent ranking results, a lineage tool tracing a metric, or a governance system classifying sensitive data. The bottleneck has moved to the data layer, and most data layers encode less than these workloads need.
Metadata tells you what data exists. Semantics tell you what it means. Once that meaning lives in the context layer and is available to every workload that reads from it, the calculus of deploying AI against enterprise data changes. “Confident-but-wrong” is the failure mode that audit and compliance teams flag, the kind regulators ask about under GDPR, SOX, and the new wave of AI-governance frameworks, and the kind that erodes the trust data teams have spent years building. A semantic layer removes that failure mode from production.
Semantic intelligence is a category claim. Discovery, lineage, quality, observability, and governance all read from the same foundation. The text-to-SQL result above shows the same architecture applied to one workload, and the architecture works the same way on the others.
When you evaluate AI-powered data tools, test the layer that lets the model interpret your data the way your business does. Ask what the model reads before it answers, and check whether that context comes from the same source as your discovery, lineage, and governance workloads. Anything else is a model upgrade waiting to let you down.
See Collate AI Analytics and AskCollate and explore how a semantic layer changes what your AI can answer.
Frequently asked questions
Why does text-to-SQL accuracy collapse on real enterprise data?
On academic benchmarks like Spider 1.0, top models exceed 85% execution accuracy. On Spider 2.0, which uses real enterprise databases, GPT-4o drops to roughly 10%. The drop reflects three problems the model cannot solve from a schema alone: ambiguous business terms, hundreds of tables with naming conventions only the team that built them understands, and business logic that lives outside the data in someone's head or scattered documentation. Without an additional layer that supplies that context, the model substitutes its best statistical guess.
What is semantic context for LLMs accessing enterprise data?
Semantic context is the meaning layer the model needs in order to translate a business question into the right SQL. It covers more than column descriptions. The layer includes glossary definitions for business terms, profiling statistics about which tables get queried, and knowledge-center entries that capture business rules. It also covers metric definitions that match the formulas finance uses to report. A semantic layer makes that meaning available to the model around the clock, so the model can pick the right tables and apply the right rules.
How does a semantic context graph differ from a traditional data catalog?
A traditional data catalog inventories what data exists and may include a business glossary that defines terms. It records metadata about each asset, like owner, schema, and classification, without showing the relationships between those terms or between the data they describe. A semantic context graph unifies metadata, semantics, and the relationships between them in one structure. It encodes which tables get queried for "loyal customer," how "net revenue" is computed, and which event defines a session. AI agents need those relationships to translate a business question into the right query. A catalog alone cannot answer that translation step.
What did Collate's three-dataset benchmark measure?
The benchmark compared base text-to-SQL against AskCollate, with both setups using Sonnet 4.5 as the underlying model. We ran the same evaluation on an internal Collate dataset, the public ACME Insurance benchmark, and a subset of Spider 2.0-Snow. The only variable was whether Collate's semantic layer was in scope. Adding semantic context lifted execution accuracy from 10.8% to 76.5% on the Spider 2.0-Snow subset and reached 100% on the ACME Insurance benchmark.
What should I look for when evaluating text-to-SQL tools?
Test how the tool decides which tables to query, not only how it generates SQL once tables are selected. Ask whether the tool reads from the same metadata layer that powers your discovery, lineage, and governance workloads, or whether it maintains a separate context store. A tool with a documentation agent that keeps column descriptions current and a profiling agent that surfaces real table usage will outperform a tool that relies on glossary entries alone.
Does adding semantic context affect more than accuracy?
Yes. When the model has the right tables and definitions in front of it before generating SQL, it does not waste tokens exploring wrong joins or retrying failed query plans. Better context produces faster answers. When data is sparse or undocumented, semantic context also prevents agents from exhausting their iteration budget and returning errors instead of answers. Accuracy improvements and compute savings come from the same architectural change.