Data Lineage Tools: Key Features and 8 Solutions to Know in 2026
What Are Data Lineage Tools?
Data lineage tools are software solutions designed to track the flow of data throughout its lifecycle in an organization’s data environment. They reveal where data originates (data sources), how it moves and changes across systems (transformations), and where it ultimately ends up (destinations).
These tools collect metadata from various data platforms, databases, ETL jobs, and analytics tools, mapping all data movement and transformation processes. This end-to-end visibility is essential in modern data ecosystems, which often span on-premises systems, multiple clouds, and hybrid infrastructures.
By using data lineage tools, teams can build an accurate map of their data pipelines and transformations. This map clarifies not only the technical paths of data, but also the dependencies, ownership, and history associated with datasets. Organizations use this visibility to troubleshoot issues, maintain data quality, support compliance, and accelerate changes to data architectures.
Benefits of Using Data Lineage Tools
Adopting data lineage tools provides organizations with several operational, analytical, and governance advantages:
- Improved data quality: Lineage tools help identify and fix issues in data pipelines by exposing the origin and transformation of incorrect or inconsistent data. This reduces the spread of errors and ensures more accurate reporting and analytics.
- Enhanced data governance: Clear lineage supports compliance with regulations like GDPR and HIPAA by showing how sensitive data flows and where it resides. It also helps enforce data stewardship responsibilities and access controls.
- Faster root cause analysis: When a data issue arises, lineage tools allow teams to trace it back to the source quickly. This speeds up troubleshooting by eliminating guesswork and reducing downtime for affected processes.
- Informed decision-making: By offering transparency into the origins and transformations of data, lineage tools help users assess data credibility. This improves confidence in the insights generated from data and leads to more reliable business decisions.
- Increased transparency and collaboration: Data lineage visualizations and metadata make it easier for technical and non-technical teams to understand and discuss data processes. This shared visibility encourages cross-functional collaboration and accountability.
Key Features of Data Lineage Tools
Automated Lineage Extraction and Discovery
Modern data environments contain thousands of datasets and complex transformation logic. Manual tracking is no longer viable. Automated lineage extraction uses connectors, APIs, and metadata scanning to discover data movement across platforms—databases, ETL tools, data lakes, warehouses, and reporting systems—without manual intervention.
This automation ensures that lineage stays up-to-date as systems evolve. Tools often include parsers for SQL, Python, Spark, and other transformation languages to reconstruct lineage directly from code and logs.
End-to-End Visualization
Effective data lineage tools provide intuitive visual interfaces that show the entire data flow—from source to destination—in a graph or network format. These visualizations make it easy to understand complex dependencies, identify bottlenecks, and communicate data flows across teams.
Users can navigate upstream or downstream to explore the impact of changes or understand data origins. Advanced tools allow filtering by dataset, transformation, or system to reduce noise and focus on relevant paths.
Impact Analysis and Root Cause Analysis
When making changes to a schema, pipeline, or data source, understanding the ripple effect is critical. Impact analysis allows users to assess downstream dependencies before implementation. This prevents breakage in reporting tools, dashboards, or dependent systems.
Conversely, root cause analysis lets users trace errors or anomalies upstream to the original source or transformation step. Together, these capabilities reduce the time needed to plan changes or resolve incidents.
Table-Level and Column-Level Lineage
Granularity in data lineage is crucial for detailed troubleshooting and compliance. Table-level lineage maps the movement of whole tables between systems, which is helpful for broad oversight and architecture reviews.
However, many issues and compliance questions require a finer-grained view. Column-level lineage drills down to show how individual data elements—such as customer addresses or financial figures—change from source to destination, revealing transformations, joins, and enrichment steps. Column-level lineage helps data governance teams track specific sensitive attributes, while engineers benefit from precise debugging when a single field is problematic.
Multi-Service Lineage Views
Data doesn't reside in a single platform. It flows through a variety of services such as cloud data warehouses, on-premises databases, BI tools, and orchestration layers. Multi-service lineage allows organizations to see data movement across these heterogeneous systems in a unified view.
This feature provides contextual understanding when a dataset is transformed in one tool, loaded in another, and visualized in a third. It is essential for managing hybrid and multi-cloud environments where data paths are often non-linear and distributed.
Lineage Propagation
Lineage propagation refers to the ability of tools to track how lineage metadata evolves as data moves and transforms. Instead of simply capturing static lineage snapshots, propagation ensures that lineage updates dynamically as changes occur in source systems or transformation logic.
For example, when a column is renamed or a new transformation is introduced, lineage tools can propagate those changes through the data flow, maintaining accuracy. This capability is vital for keeping lineage information reliable over time and for supporting continuous delivery in data pipelines.
Data Quality and Data Catalog Integration
Leading lineage tools integrate with data quality and data catalog platforms to create a more complete metadata ecosystem. Quality rules and profiling results can be overlaid on lineage graphs, highlighting where data issues originate or propagate.
Integration with data catalogs allows users to search lineage by business terms, tags, or classifications. This enriches the technical view with business context and improves data discovery. These integrations support unified governance, where lineage, quality, and cataloging reinforce each other.
Notable Data Lineage Tools
1. Collate®

Collate is an AI-powered metadata platform unifying discovery, observability, and governance for modern data teams, powered by the open-source OpenMetadata project.
General features include:
- Unified knowledge graph: Centralizes metadata with 100+ turnkey connectors across the full ecosystem of data sources for automated cataloging, profiling, and mapping.
- AI-Powered Semantic Intelligence: Conversational AI and agents understand data meaning to generate descriptions, identify PII, create tests, and accelerate productivity.
- Integrated Collaboration & Workflows: Drive data culture across data teams through conversations, activity feeds, announcements, audit trails, and approval workflows.
- API-First Architecture: Built on a modern, open architecture with REST APIs, Python/Java SDKs, and plugin frameworks for integration with existing operations.
- Designed for Enterprise Production: Cloud-native architecture scales to millions of assets, with a customizable UI accessible to thousands of technical & non-technical users.
Data lineage features include:
- End-to-end column-level lineage: Tracks data flow across heterogeneous sources, pipelines, and dashboards, integrated with observability, quality, and governance.
- Automated lineage extraction: Parses query logs and history, coupled with API and SDK integrations, as well as AI-powered and manual update capabilities.
- Lineage map layers: Customizable lineage visualization across data domains, products, and services, with advanced filtering by asset type, ownership, and tiers.
- Intelligent impact & root cause analysis: Perform forward and backward analysis using map and tabular views of dependencies, with ownership and quality correlation.
- Lineage-driven governance: Overlay ownership, quality results, classification tags on lineage graphs, with automated lineage propagation of sensitive data classifications.


2. Atlan


Atlan is a data and AI governance platform with discovery, policy management, integrations, and developer tooling, including onboarding guides and enterprise deployment options.
General features include:
- Search and profiling: Search, discover, and profile assets across connected systems to help users find and understand data used in analytics and AI workflows.
- Policies and contracts: Create data contracts and policies to govern access and management, supporting stewardship and controls across the data ecosystem.
- Playbooks automation: Automate rule-based metadata updates at scale, enabling bulk curation and consistent enrichment across large catalogs.
- Integrations and setup: Integrate through automation, collaboration, and prebuilt connectors, with setup guides for Snowflake, Databricks, and Power BI environments.
- Developer tooling: Use developer APIs, client SDKs for Java and Python, and packages to programmatically interact and extend platform capabilities.
Data lineage features include:
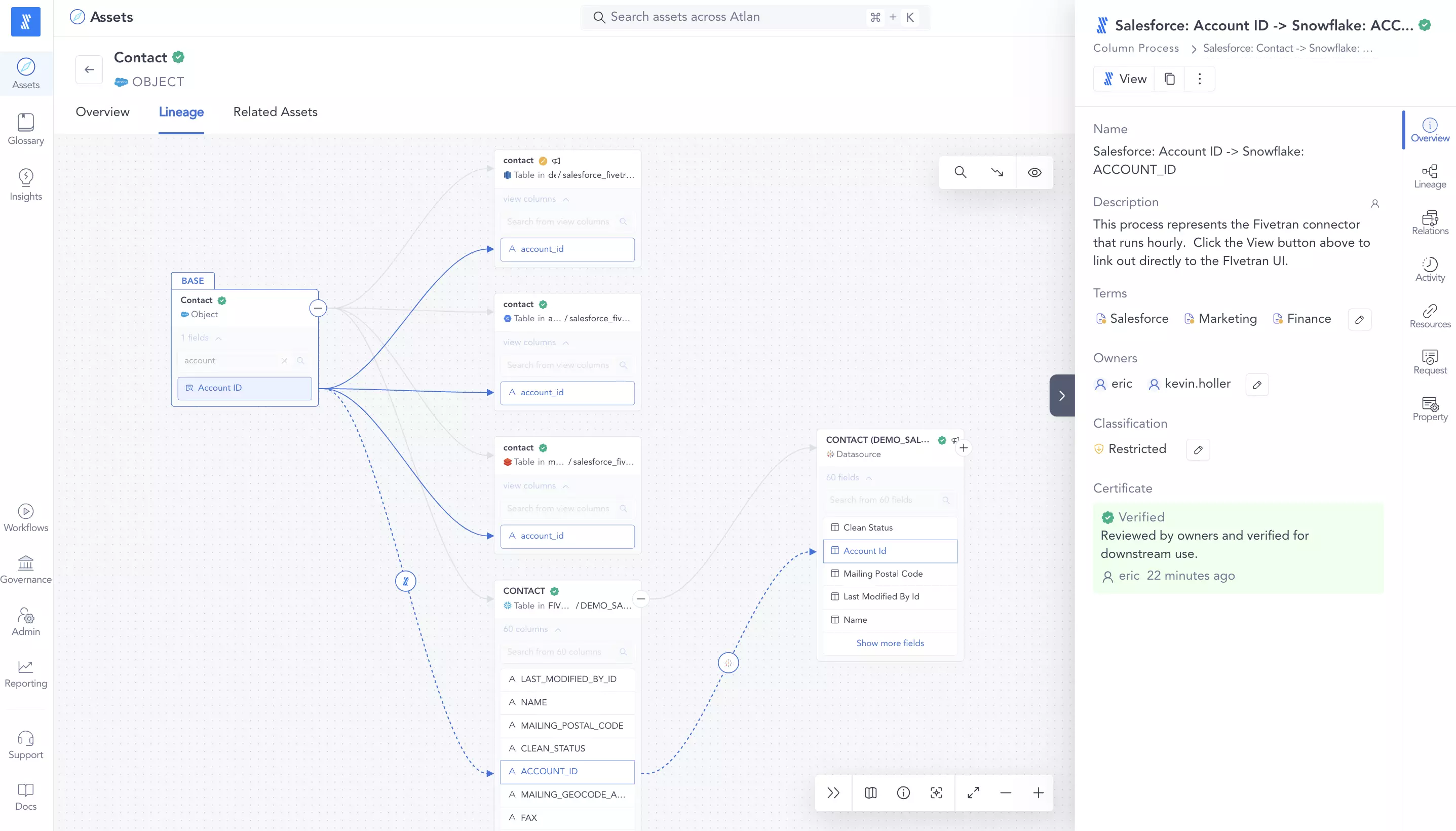
- Column-Level Lineage: Tracks relationships at the column level for precise visibility into how data flows and transforms across systems, moving beyond table-level insights.
- Automated SQL Parsing: Automatically parses SQL queries to generate lineage, mapping dependencies between columns and datasets.
- Cross-System Integrations: Connects warehouses and BI tools to provide unified lineage across data environments.
- Interactive Exploration: Offers smooth navigation, node-level controls, and zooming to explore lineage visually and understand data impact paths.
- In-Line Actions: Enables collaboration directly within lineage views—alert users, create Jira tickets, or message asset owners in Slack when issues arise.

3. DataHub

DataHub is an open-source metadata platform that provides data cataloging capabilities with metadata modeling and lineage tracking across data systems.
General features include:
- AI & Data Context Platform: Provides metadata for AI to understand and use data across different use cases.
- AI-Enhanced Data Catalog: Uses automation and AI to enrich metadata, generate documentation, and propagate context across related assets.
- Scalable for Production: Designed to meet enterprise demands for scale, reliability, and low-latency metadata operations.
- Personalized Discovery Experience: Offers tailored search and recommendations for different user personas, including analysts, engineers, and scientists.
- Browser and Tool Integration: Provides a Chrome Extension for seamless dataset discovery within BI and analytics tools.
Data lineage features include:
- Comprehensive Lineage Coverage: Supports lineage tracking between datasets, data jobs, dashboards, and charts.
- Table- and Column-Level Lineage: Captures both entity-level and fine-grained column-level relationships for precise impact analysis.
- Programmatic Lineage Management: Python SDK enables adding, retrieving, and updating lineage definitions through simple API calls.
- Automatic Lineage Inference: Parses SQL queries to infer upstream and downstream datasets, automatically creating lineage links and query nodes.
- Flexible Column Mapping: Supports fuzzy matching (auto_fuzzy), strict name matching (auto_strict), or custom mapping between columns.


4. Alation Data Lineage


Alation offers business and technical lineage with map-like overlays for data quality, trust, and metadata, designed to make flows and dependencies understandable across teams.
General features:
- Collaborative Data Catalog: Search and discover data assets with crowdsourced knowledge, user-generated queries, and conversational interfaces
- Data Governance Framework: Establish policies, stewardship assignments, and certification workflows to ensure data is properly managed and trusted
- Trust and Quality Indicators: Display trust flags, endorsements, and quality metrics directly on data assets to help users assess reliability and fitness for use.
- Behavioral Analytics: Track how users interact with data to surface popular datasets, identify experts, and recommend relevant assets based on usage patterns.
- Integration Ecosystem: Connect with data warehouses, BI tools, ETL platforms, and collaboration tools through native connectors and APIs
Data lineage features include:
- End-to-end visibility: Provide end-to-end lineage views showing data flows, relationships, asset health, and impact analysis for assessing dependencies across systems.
- Business lineage overlays: Offer Business Lineage with map-like overlays for data quality, trust flags, and business metadata, plus summary panes that supply contextual details.
- Technical mapping with context: Automate technical data flow mapping and layer business context, with filters and groups to tailor views to specific situations.
- Transparency and flags: Increase transparency with maps that include data health, policy information, key points, and deprecation flags to highlight trustworthy or risky assets.
- Cost control and migrations: Support cost control and migration planning by removing duplicate reports, enabling impact analysis, and reducing root cause investigation time.


5. Secoda Data Lineage


Secoda provides automated end-to-end lineage and ERD mapping across the data stack, with change notifications, scheduled updates, and manual adjustments through a visual interface.
General features include:
- AI-Powered Documentation: Automatically generate and maintain documentation for tables, columns, and metrics using AI
- Universal Search: Search across all connected data sources, documentation, and conversations from a single interface to quickly locate assets and answers.
- Data Dictionary Management: Build and maintain centralized data dictionaries with definitions, ownership, and business context that sync across all connected systems.
- Collaboration Workspace: Enable team discussions, questions, and knowledge sharing directly within the platform through threaded conversations and notifications.
- No-Code Integration: Set up connections to data warehouses, databases, and BI tools without technical expertise through guided workflows and pre-built integrations.
Data lineage features include:
- End-to-end mapping: Map end-to-end lineage across warehouses, databases, and BI tools, using queries, foreign keys, primary keys, and attributes to capture dependencies.
- Automated updates: Schedule recurring extractions to keep lineage current, with no-code integrations and quick setup for permissions and settings.
- Change notifications: Receive notifications on updates affecting tables, columns, documentation, or reports, helping owners address issues before disrupting critical outputs.
- Manual graph editing: Adjust lineage graphs by adding relationships through a drag-and-drop visual interface for flexible, manual refinement of automated maps.
- Communication and testing: Announce upcoming changes to upstream or downstream users via Slack, email, or inbox, and visualize data quality tests with automated failure alerts.


6. Informatica Data Lineage

Informatica’s Cloud Data Governance and Catalog automates lineage capture and visualization, parses transformation code, and supports impact analysis and compliance reporting.
General features include:
- Enterprise Data Catalog: Discover, understand, and govern data assets across hybrid and multi-cloud environments with AI-powered cataloging and classification.
- Data Quality Management: Profile, monitor, and improve data quality with built-in rules, scorecards, and remediation workflows integrated throughout the platform.
- Privacy and Compliance Controls: Identify, classify, and protect sensitive data with automated PII detection, masking policies, and compliance reporting.
- Collaborative Governance: Establish data stewardship, approval workflows, and policy management with role-based access and audit trails for accountability.
- Cloud-Native Architecture: Deploy on AWS, Azure, or Google Cloud with scalability, high availability, and support for data sources across on-premises and cloud.
Data lineage features include:
- Automated extraction: Automatically extract lineage to provide detailed and summary views of data movement across pipelines, improving visibility into sources, transformations, and destinations.
- Code parsing: Parse SQL scripts, stored procedures, and AI or machine learning code to derive transformation lineage embedded within processing logic.
- Granular impact analysis: Track lineage from system-level to column-level to support detailed impact analysis and change management across complex environments.
- Visualization and relationships: Visualize lineage and underlying relationships to improve data literacy and trustworthiness for analytics and AI initiatives.
- Compliance reporting: Support regulatory compliance needs by providing extensive lineage suitable for reporting obligations and risk mitigation across regulated environments.

7. Apache Atlas


Apache Atlas is an open-source metadata management and data governance framework that provides organizations with a centralized catalog of data assets.
General features include:
- Open Metadata Management: Provides a centralized platform for managing metadata across the enterprise, supporting both Hadoop and external systems.
- Extensible Type System: Includes predefined metadata types for common Hadoop components (e.g., Hive, HDFS) and allows users to define custom metadata models with inheritance and relationships.
- Entity and Relationship Management: Represents metadata as entities (instances of types) with detailed attributes and object references to model complex data dependencies.
- Comprehensive REST APIs: Offers APIs for creating, updating, and retrieving metadata types, entities, and relationships, simplifying integration with external tools and data pipelines.
- Dynamic Classification System: Enables creation of custom classifications (e.g., PII, Sensitive, Data_Quality) with associated attributes for fine-grained metadata tagging.
Data lineage features include:
- End-to-End Lineage Tracking: Captures and visualizes how data moves across processes, from source to destination, across Hadoop and non-Hadoop systems.
- Interactive Lineage Visualization: Provides an intuitive UI to explore lineage relationships between datasets, tables, views, and files.
- Lineage APIs: Exposes REST APIs for accessing, adding, and updating lineage information programmatically, supporting integration with ETL tools and orchestration platforms.
- Classification-Aware Lineage: Automatically propagates classifications along lineage paths, ensuring that governance labels like PII or Sensitive remain consistent in downstream assets.
- Dynamic Propagation Control: Offers propagation control flags at both entity and lineage edge levels to enable or disable automatic classification inheritance.


8. OpenLineage

OpenLineage is an open specification and platform for lineage collection and analysis, with a standard event API, a reference backend (Marquez), and broad tool integrations.
Key features include:
- Standard event API: Provide a standard API for emitting lineage events about runs, jobs, and datasets from schedulers, warehouses, analysis tools, and SQL engines.
- Reference repository and libraries: Include a reference metadata repository, Marquez, alongside language libraries and integrations to capture and store lineage consistently.
- Flexible deployments: Support deployment patterns from simple single-consumer setups to complex topologies with multiple consumers processing lineage data.
- Context for analysis: Enable impact analysis and root cause investigation by capturing contextual metadata that describes how data is produced and used.
- Open collaboration: Foster open collaboration through an open specification, Slack community, GitHub project, and public Technical Steering Committee meetings.


Related content: Read our guides to data lineage examples and DataHub lineage
Conclusion
Data lineage is foundational for building trust, transparency, and control in modern data environments. As data systems grow in complexity, the ability to track how data flows, transforms, and relates across platforms becomes essential for governance, quality, and agility. By integrating lineage into data operations, organizations can better manage risk, support compliance, and enable teams to collaborate effectively with shared visibility into how data powers business outcomes.
Fashion Retailer Mango’s Data Journey with Collate
Read the case study

Sign up to receive updates for Collate services, events, and products.
Share this article



Ready for trusted intelligence?
See how Collate helps teams work smarter with trusted data