Best Data Observability Software: Top 5 Solutions in 2025
What Is Data Observability Software?
Data observability software helps organizations monitor and understand the health and performance of their data pipelines and the data itself. It provides insights into data quality, reliability, and performance, enabling proactive issue detection and resolution.
As organizations rely on larger volumes of data and more complex architectures, the pressure to maintain reliable, trustworthy data grows. Data observability software helps by uncovering hidden problems early, reducing downtime, and improving confidence in analysis. It also enables collaboration between operations, data engineering, and governance teams.
Data observability software typically offer the following features:
- Monitoring and anomaly detection: Observability tools continuously monitor data pipelines and datasets, identifying anomalies, errors, and unexpected behavior.
- Data quality assurance: They help ensure data completeness, consistency, and accuracy, enabling better decision-making based on trusted data.
- Proactive issue resolution: By detecting issues early, these tools minimize data-related failures, reduce downtime, and prevent costly disruptions.
- Performance optimization: Data observability helps identify bottlenecks and performance issues in data pipelines, allowing for optimization and improved resource utilization.
- AI and automation: Many tools utilize AI to analyze historical data, automate anomaly detection, and provide recommendations for issue resolution.
Popular tools, which we cover in more detail below, include:
Key Features and Benefits of Data Observability Software
Monitoring and Anomaly Detection
Data observability software continuously tracks datasets, dataflows, and pipeline health. These tools go beyond basic checks to analyze volume, frequency, schema changes, and more. When an abnormality is detected—such as a sudden drop in row count or a schema drift—the system flags it, often in real-time. Automated alerts ensure teams know immediately when thresholds are breached, minimizing the time to investigate and resolve issues.
Anomaly detection leverages pattern recognition, sometimes augmented with machine learning, to recognize subtle deviations. For example, a spike in missing values or a gradual increase in latency can indicate larger systemic concerns that simple monitoring might overlook.
Data Quality Assurance
Ensuring data accuracy and reliability is a core function of data observability platforms. They perform ongoing checks for data completeness, consistency, timeliness, and conformity to predefined standards or business rules. Automated data quality dashboards highlight issues such as duplicates, nulls, outliers, or logical inconsistencies, empowering data teams to address root causes without sifting through massive datasets manually.
Continuous data quality enforcement is especially critical in environments with frequent ingestions from external sources or third-party integrations. Effective observability software integrates data quality metrics with pipeline operations so errors never go unnoticed. This reduces downstream impacts on analytics, machine learning models, and business reports.
Proactive Issue Resolution
Modern data observability tools provide context and recommendations to support remediation of data issues. When an anomaly or failure occurs, observability software correlates logs, traces, and metadata to show exactly where and when the issue emerged. This context helps teams rapidly isolate the fault, whether it stems from a code deployment, infrastructure change, or upstream data provider.
Proactive resolution also involves root cause analysis and issue lineage tracking. By connecting errors to their source and mapping dependencies, observability software minimizes guesswork and repeat incidents. Many platforms offer automated workflows for triage and escalation, ensuring that the right personnel are notified with the information needed to fix issues.
Performance Optimization
Data observability solutions provide granular visibility into pipeline performance, helping organizations identify inefficiencies or bottlenecks. By monitoring processing times, resource usage, and throughput at every stage, these tools allow teams to fine-tune workloads and balance loads across environments. Performance metrics are correlated with data volumes and operational events to surface underlying causes of slowdowns or resource contention.
Ongoing performance optimization is crucial for cost control and SLA adherence, especially as data infrastructure scales. Observability tools enable continuous tuning, helping organizations maximize cloud or on-premises investments.
AI and Automation
Modern data observability solutions leverage AI to improve detection, diagnosis, and resolution workflows. Machine learning models analyze patterns across historical incidents and operational telemetry to predict issues before they disrupt business-critical processes. These predictive capabilities automate anomaly identification and recommend remediation actions based on context and past resolutions.
Automation accelerates incident response and routine maintenance, reducing manual workloads for data engineers and analysts. Automated playbooks can trigger data pipeline reruns, notify stakeholders, or spin up resources dynamically in response to detected issues.
Data Observability Software vs. Data Monitoring
Data monitoring tools traditionally focus on surface-level metrics like pipeline statuses, system health, and alerting based on static rules. They can confirm that jobs ran and systems are online but lack depth in surfacing data-specific issues or providing end-to-end views of the data lifecycle. As a result, deep-seated data quality or lineage issues can escape detection, impacting business decisions and operational reliability.
Data observability software takes a more holistic approach. It encompasses monitoring but also adds context from traces, logs, and metadata, unifying insights across data infrastructure. Observability reveals not just whether something is broken, but why, where, and how to fix it, automatically correlating system and data events. This shifts teams from reactive troubleshooting to proactive, informed management, supporting higher data reliability and agility.
Notable Data Observability Software
1. Collate®

Collate is an AI-powered data observability platform that gives organizations end-to-end visibility into their data pipelines, health, and quality. It eliminates the need for multiple point solutions by unifying data observability with data discovery and governance capabilities. Built on the open source OpenMetadata project, Collate offers AI-driven automation and real-time monitoring capabilities that reduce mean time to detect (MTTD) and mean time to resolve (MTTR), making it easier to troubleshoot and prevent data issues across the entire stack.
Key features include:
- Real-time pipeline monitoring: Tracks ETL job execution, detects failures, and surfaces upstream and downstream quality issues through a centralized health dashboard.
- AI-powered data quality testing: Generates no-code and SQL-based tests for data accuracy, freshness, and custom metrics automatically on Day 1, helping teams catch quality problems early.
- Automatic data profiling: Offers deep insights into the shape of datasets, including null values, distributions, and other key metrics to support data validation.
- Incident management and collaboration: Centralizes alerts and issue tracking with an integrated incident manager that supports assignment, coordination, and communication across teams.
- Custom alerting and change management: Configurable notifications and schema change alerts ensure teams are informed of impactful modifications or failures.
- Root cause analysis and lineage views: Combines quality results with lineage information to help teams trace errors back to their origin and assess downstream impact.
- Cost and governance optimization: Designed to support modern data practices with AI-driven automation for governance enforcement and resource efficiency.

2. Monte Carlo


Monte Carlo is a data and AI observability platform to detect, resolve, and prevent data quality issues across modern data stacks. It automates monitoring and incident response using machine learning, enabling teams to pinpoint root causes and minimize downtime.
Key features include:
- Automated monitoring: Uses AI to automatically deploy monitors across datasets, detecting issues like schema changes, null spikes, or row count anomalies with minimal setup.
- Custom rule creation: Allows teams to define business-specific logic for data quality validation to supplement built-in metrics.
- Root cause analysis: AI-powered tools correlate incidents across systems and metadata to determine where and why data issues originated.
- Impact analysis: Highlights which teams, tables, or downstream assets are affected by an incident, improving response targeting.
- Cross-system lineage: Visualizes data flow across systems, helping trace issues back to their source and understand dependency impacts.

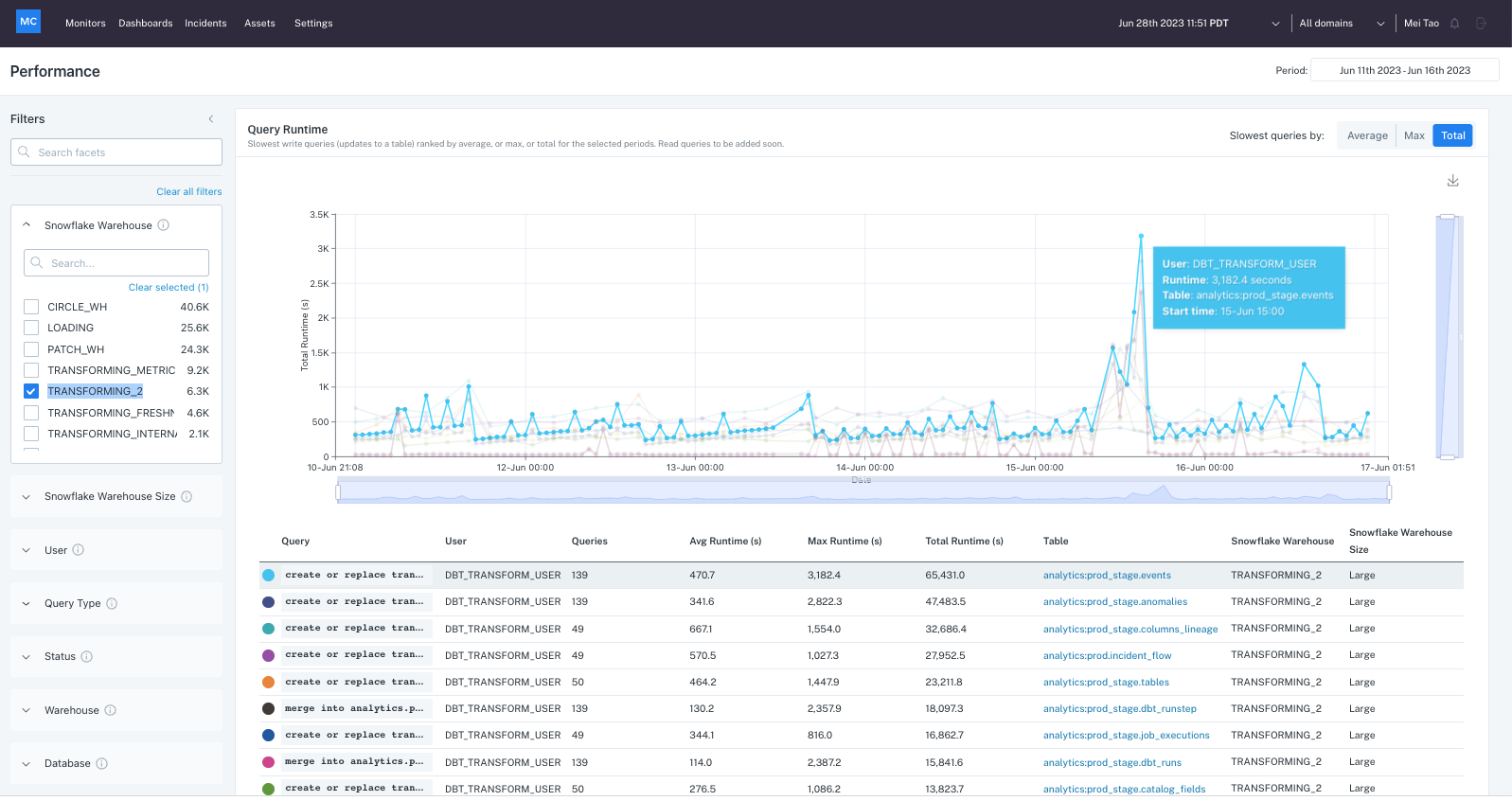
3. Bigeye

Bigeye is an enterprise data observability platform for both modern and legacy data stacks. Using lineage-enabled data observability, it allows teams to identify, triage, and resolve data incidents. The platform provides monitoring and alerts, enabling organizations to proactively manage their data pipelines.
Key features include:
- Lineage-enabled data observability: Tracks data lineage at a granular level to provide visibility into data flows, enabling faster issue detection and resolution.
- Enterprise coverage: Supports a wide range of data environments, including both modern and legacy stacks, with integration across cloud, on-premises, and hybrid systems.
- Automated root cause analysis: Leverages lineage to automatically pinpoint the root cause of data issues and assess their downstream impacts.
- Real-time alerts: Sends timely notifications when data issues arise, ensuring that teams can resolve problems before they affect decision-making.
- Data health summaries for business stakeholders: Provides clear, lineage-driven summaries of data health for non-technical users.

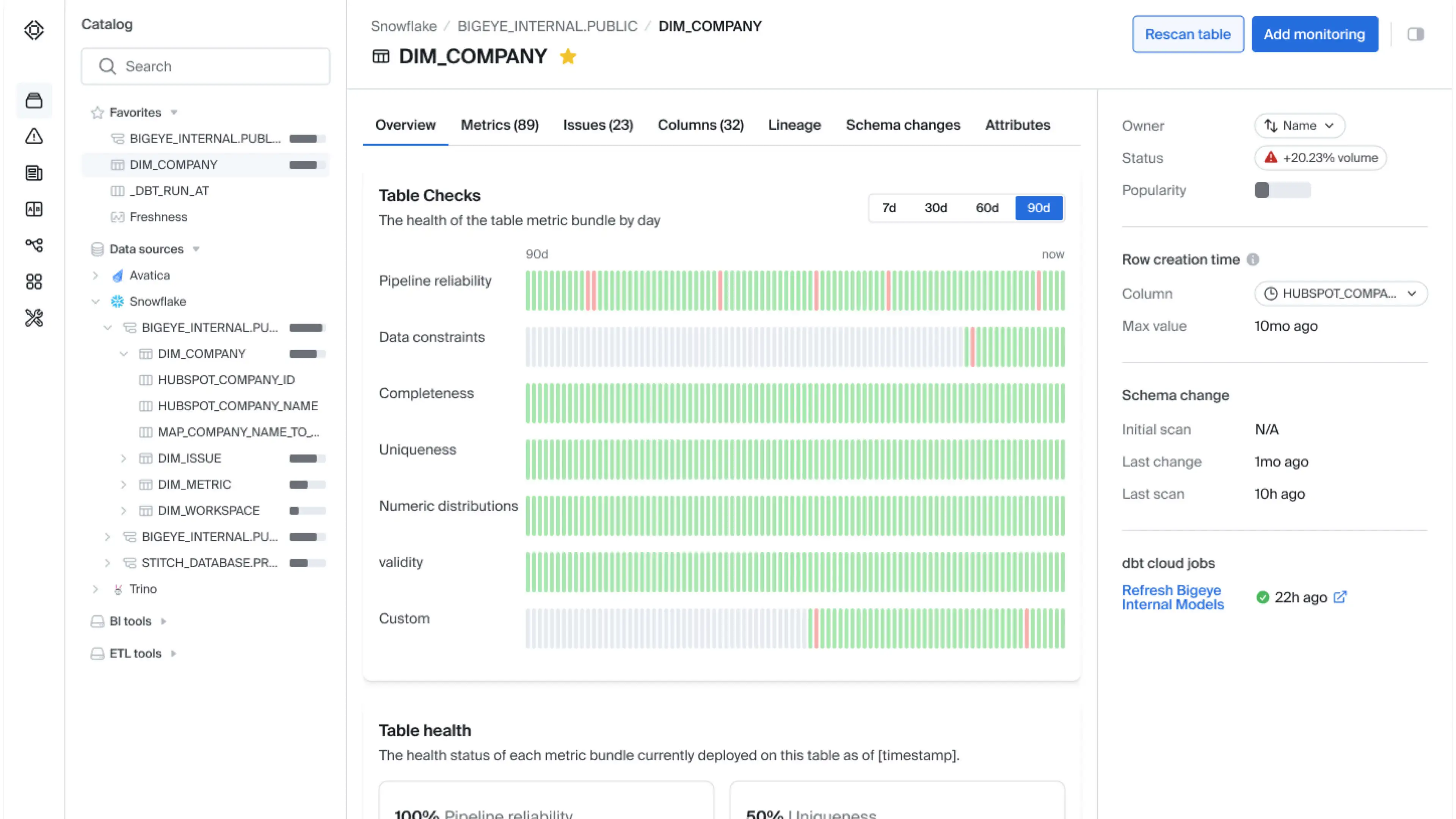
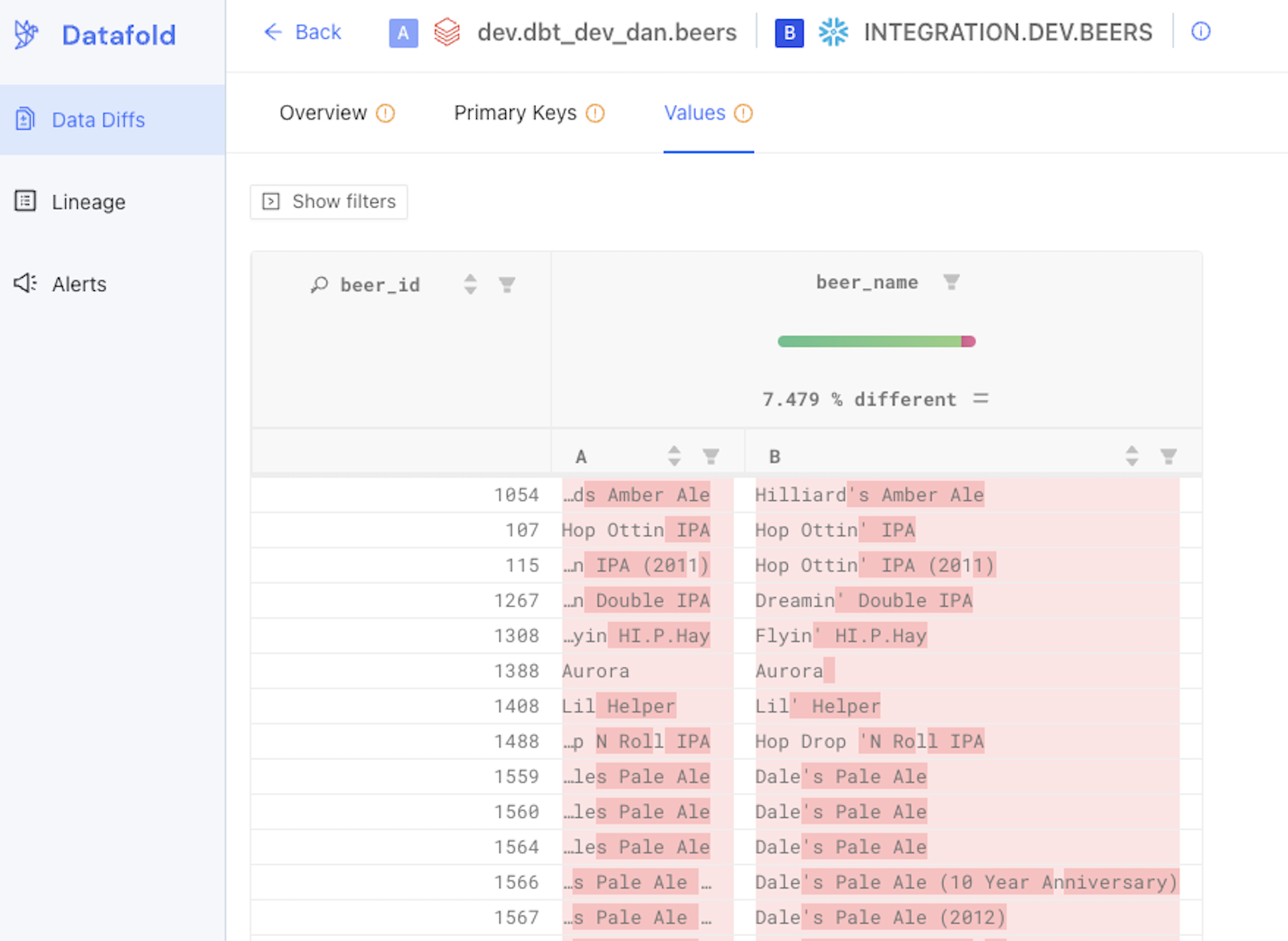
4. Datafold


Datafold is a data monitoring platform to prevent downtime and detect data quality issues early in the data pipeline. By focusing on upstream data monitoring, it helps teams maintain data integrity and identify discrepancies before they become major issues.
Key features include:
- Data diffs: Identifies discrepancies between source and target databases.
- Metrics monitoring: Leverages machine learning to detect anomalies in key metrics like row count, data freshness, and cardinality.
- Data tests: Automates data validation using custom rules, detecting record failures such as invalid data or duplicates for rapid resolution.
- Schema change alerts: Provides notifications when unexpected schema changes occur, such as structural or column-type modifications.
- Real-time alerting: Integrates with communication platforms like Slack, PagerDuty, Email, and Webhooks.
5. Secoda


Secoda is an observability platform to automate monitoring, alerting, and testing to ensure data reliability and trust across the data pipeline. With its no-code setup and comprehensive visibility into data pipelines, query performance, and costs, it allows teams to maintain data quality and operational efficiency.
Key features include:
- Data pipeline monitoring: Provides visibility into data pipelines, queries, costs, and jobs.
- Data quality monitoring: Allows teams to set up no-code monitors on key tables to track freshness, uniqueness, and other quality metrics.
- Query performance monitoring: Offers visibility into query usage, performance, and dependencies, helping teams catch slow queries early.
- Cost monitoring: Breaks down costs by user, warehouse, or role to identify optimization opportunities.
- Job performance monitoring: Centralizes tracking and analysis of jobs across multiple data tools.
Conclusion
Data observability software has become essential for ensuring the reliability, accuracy, and performance of modern data systems. By providing deep visibility into data pipelines and automating the detection of anomalies, these tools empower organizations to proactively address issues before they impact operations or decision-making. As data ecosystems grow more complex and distributed, proper observability practices enable teams to maintain trust in their data.




